”Jag trodde jag visste precis hur allt skulle bli / Men jag visste inget / Nästan ingenting”
~ Allt ska bli bra, Vånna Inget (2019)
För SVT Barns playtjänst är det inte tjänsten i sig som behöver optimeras och följas upp. Eller, visst behöver vi monitorera för att upptäcka lågpresterande features och exponeringar. Men på det hela är det innehållet och publiceringstempot som gör den stora skillnaden.
När jag började analysera och experimentera med SVT Barns videotjänst gjorde jag precis som jag brukade. Jag fokuserade nästan 100% på tjänsteutvecklingen.
Alltså UX, features, visuell design, interaktionsdesign, relevans i rekommendationer, sökresultat. Och så vidare. Vi testade designidéer och exponeringsmodeller, A/B-testade listordningar och olika sätt att lyfta innehåll.
Några hypoteser kunde valideras, lojalitet och räckvidd kunde förbättras en aning här och där. Men oftast var de långvariga effekterna begränsade när hänsyn hade tagits till kannibalism och suboptimering.
Spoiler: Nu lägger jag kanske 10% av min tid på att prioritera, följa upp och validera hypoteser som rör features och gränssnitt. Varför? Analys, experimenterande och snabbt lärande om det som rör innehåll och publicering får betydligt större impact för SVT än själva tjänsteutvecklingen.
Det tog mig styvt ett år att förstå i min egna ängslighet.
Så djupt rotad var jag i tanken att gränssnitt och features alltid påverkar KPI:er och användarupplevelse mest.
Men jag visste nästan ingenting. Bara att jag måste hitta andra sätt att följa upp på. Lära mig älska bomben.
Uppföljning av publicering
De flesta streamingtjänster mäts på räckvidd: veckoräckvidd och/eller dygnsräckvidd. Lite förenklat påverkas räckvidden av tillströmning av nya användare och graden av lojalitet. Lojaliteten påverkas av att det alltid finns relevant innehåll att konsumera, som dessutom är lätt att hitta.
Utmaningen för de som lägger tablå (som i sin tur blir tillgängligt innehåll i Play-tjänsterna beroende på olika avtal) är att ständigt se till att olika användarsegment har relevant innehåll att titta på. Det bör inte vara för stora dippar i utbudet under årscykelns gång.
På episodnivå gäller det också att klura ut hur innehållet ska släppas för att skapa bra lojalitet till både titeln och tjänsten i stort.
- Ska en släppa alla 20 episoder direkt, eller
- sprida ut dem över tid för bästa totala räckvidd?
- Och hur lång publiceringperiod är egentligen optimalt?
Strategin (eller egentligen hantverket) beror givetvis på rättigheter, genre, målgrupp, antal tillgängliga episoder samt episodlängder. Men generellt kan en säga att en måste släppa tillräckligt mycket (=minuter innehåll, ej antal episoder) första veckan, och tillräckligt mycket per följande veckor för att skapa incitament för användaren att komma tillbaka.
En vill heller inte publicera för mycket innehåll direkt eller per följande veckor. Detta gäller framförallt högpresterande titlar, då överpublicering allt som oftast påverkar total lojalitet till tjänsten negativt.
Jag ska visa med ett exempel.
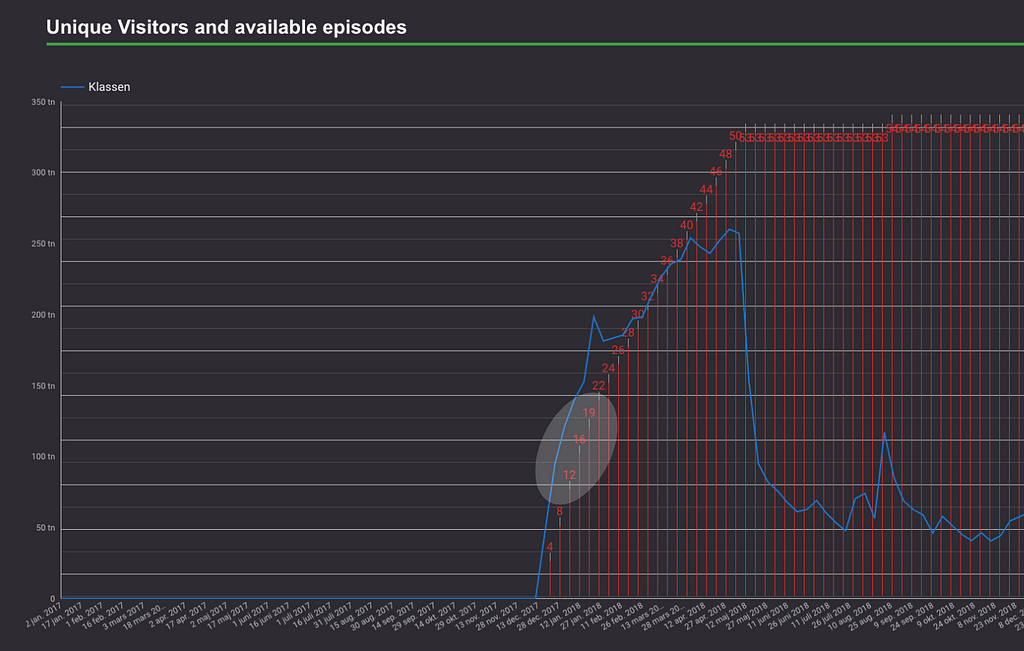
Förra året började vi visa ungdomsserien Klassen. Episoderna är ungefär åtta minuter långa och vi släppte från början fyra episoder per vecka som planerat. Redan efter några veckor stod det klart att titeln var en succé bland 9–15-åringar och drev flera hundratusen unika besökare till våra tjänster.

Totalt hade vi c:a 50 episoder att hushålla med. Fyra episoder per vecka gör att vi skulle haft tolv veckor med mycket bra räckvidd till våra Play-tjänster. Ganska snart insåg våra skarpa redaktörer att vi borde starta ett A/B-test där några användare får tre episoder per vecka, några får två episoder, samt resten får fyra episoder som tidigare.
Jag undersökte hur lojalitet och räckvidd påverkades hos de som fick färre episoder (mycket lite visade det sig) och vi gick efter endast ett par veckor över till att publicera två episoder per vecka. På så sätt såg vi till att Klassen kunde släppa nytt innehåll i ytterligare nio veckor jämfört med planerat. Vilket ledde till förhöjd lojalitet och bättre räckvidd för hela tjänsten. Samt köpte oss tid att ta fram en spinoff-titel samt pusha för liknande innehåll i flera extra veckor.
En vanlig och ganska självklar synpunkt är att det måste innebära risker att genomföra A/B-test på populära titlar som Klassen. Tänk om barnen pratar med sina kompisar och jämför hur många episoder de kan se på. Varför får inte jag alla se alla episoder?
Jag tänker så här:
Är vinsten av att lära mig större än risken att förlora användare?
Jag är av den övertygelsen att den som validerat lär sig snabbast alltid kommer ha en komparativ fördel gentemot sina konkurrenter. Den som tar minst risker lär sig sällan snabbast.
Våra redaktörers ständiga utmaning är att pricka det perfekta publiceringstempot. Här får de svart på vitt vilka tempon som fungerar bättre än andra. Högt värde, tycker de.
I det här fallet är det också ganska enkelt att minska riskerna.
- Populära titlar klarar sig ofta med att väldigt liten andel av besökarna är med i A/B-testet.
- Jag monitorerar lojalitetsutfallet under testets gång och ser jag för stora negativa avvikelser så avbryts testet.
(Med “validerat lärande” menar jag lärandet av statistiskt signifikanta och över tid hållbara kausala samband, som resultat av kontrollerade experiment. Experiment som också går att upprepa med samma resultat, givet liknande förutsättningar. Resultat som också är validerat att det inte leder till för stor kannibalism eller suboptimering.)

För att effektivisera det här lärandet har vi numera byggt ett eget skräddarsytt A/B-testverkyg för våra redaktörer så att de själva kan experimentera med hur hur episoder ska släppas. Från allt direkt till utspritt över en längre tid.
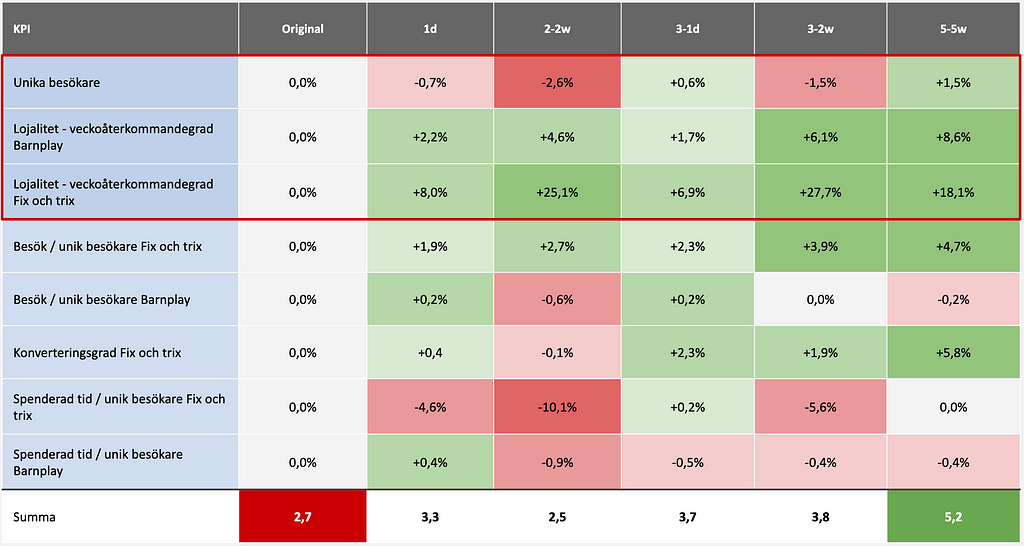
Det vi ser efter ett tiotal publiceringstempotest är att en verkar kunna påverka total veckolojalitet, total räckvidd och total spenderad tid i titeln med upp till 30%, genom att förfina och experimentera med publiceringen. Det är alltså det perfekta tempot som en försöker nejla.
Förutom publiceringsexperiment följer jag upp hur publiceringen ser ut över tid för olika målgrupper och även annan metadata (som t.ex. “0–2 år”, ”fakta”, “animerat”, ”storbarnsdrama”, etc).
- Finns det tillräckligt med helt nytt och ganska nytt (repriser) innehåll inom segmentet?
- Behöver vi justera och flytta räckviddsdrivande storbarnsdrama från hösten till våren?
Viktigt att tänka på här är att det inte räcker att publicera rätt mängd titlar och/eller rätt antal möjliga minuter att konsumera under årscykelns gång. Även (förväntad) popularitet måste portioneras ut jämnt.
Som ni förstår finns det så otroligt många skärningar, segment, metadata och dimensioner att analysera och ta beslut efter. De viktigaste klustren har jag numera bra koll på.
Men användarna är mer komplicerade än att sorteras in i sju, åtta segment.
För att addera till komplexiteten verkar det inte gå att helt hålla sig till en åldersbaserad segmentering. Ålder kan vara en mycket användbar indelning fram tills barnen fyllt sex, sju år. Men sedan verkar intresse och i viss mån kompisars påverkan och värderingar påverka tittandebeteendet. Ni förstår. Det blir för komplext att som analytiker hålla koll på alla beteendekluster.
Nästa logiska steg för oss, redan påbörjat, är att börja experimentera med machine learning för att pinga redaktörer, inköpare och programutvecklare om när innehåll behövs, för att inte tappa användare i autoklustrade segment. Mer om det sedan.
Uppföljning av exponering
I SVT Barns fall påverkar exponering både beteende och utfall. Dock mycket mindre än vad en kan tro. Eftersom vi har byggt upp ett UX-system där innehåll som en användare redan tittat på visas högt upp i tjänsten (som ”Du har tittat på”) tar den typen av exponering mycket av tittningen. Främst p.g.a. att relevansen är så hög för den här listan. Du vet vad du får.

De ytor som blir över används för att pusha för nytittning. Det är ett medvetet val att exponera historiken högt upp, lojaliteten till tjänsten minskar så fort vi gör det svårare att komma åt sin historik. Dock är placeringen av den här raden lite olika beroende på hur gammal vi tror besökaren är.
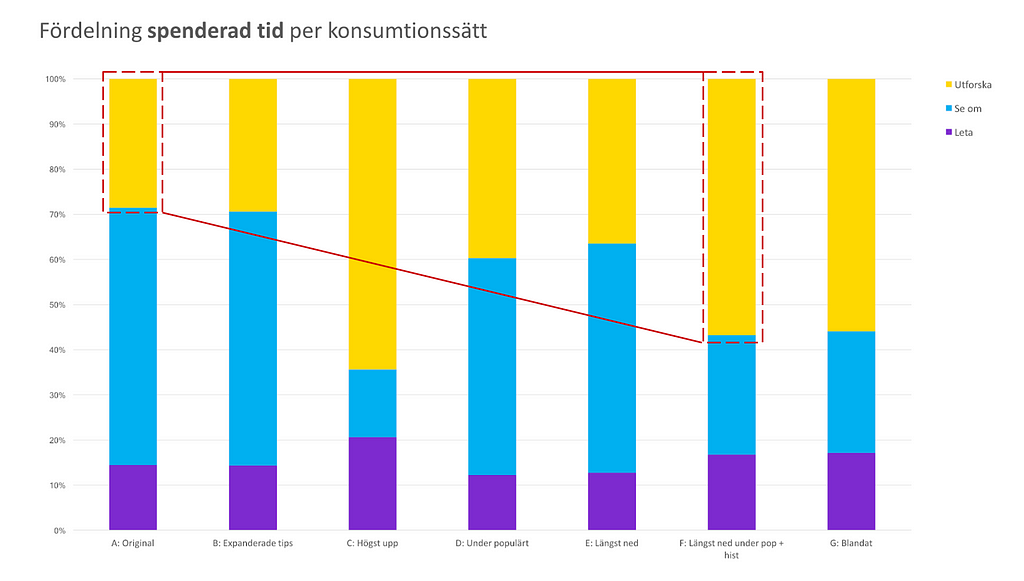
Med detta sagt så finns det fortfarande möjlighet att använda exponering för att framförallt få användare att upptäcka en titel snabbare.
Otaliga A/B-test vi genomfört visar att varken exponering eller val av affischbild påverkar titelns totala räckvidd, spenderad tid, etc. Mer än marginellt. Detta gäller på lång sikt (6–8 veckor eller längre tid beroende på publiceringsfönster). Starkt innehåll som skapar lojalitet hittas i princip ändå alltid till slut.
Dock kan vi påverka att användare upptäcker en titel flera dagar tidigare än vad som annars varit fallet. Vilket också är ett redaktionellt mål med vår verksamhet.
Uppföljningen av våra listor, slutskärmar och andra exponeringsytor görs genom att kombinera CTR-data (löftet) med kvalitet på klicken (bounce rate i kontexten samt spenderad tid/möjlig tid i episoden). Främst följer jag upp på en aggregerad listnivå, men vid behov också på positions- och titelnivå samt vilken ordning listan har.
Oftast visar det sig att titlarna i listan är betydligt mer viktiga än listan som helhet. En bra titel kan göra hela skillnaden för listans prestation.
Att redaktionellt skapa logiska listor och grupperingar ger alltså inte jättemycket tillbaka i vår kontext. Oftast.
Detta är intressant då det öppnar upp för många intressanta konceptuella idéer, där vi kan röra oss bort från vertikala listor. Istället kan vi utgå från relevansrankingmodeller på titel- och episodnivå likt EdgeRank, Instagram, Tumblr, Twitters, TikTok och andra flödesgränssnitt.
För att hålla koll på kannibalism och suboptimering mäter vi alla 25–30 listor så fort vi gör förändringar eller A/B-testar nya exponerings- och pushytor.
Exempelvis är det superenkelt att skapa nytittning genom att flytta ner historikraden något. Men det leder till sämre UX och lojalitets-KPI:erna går ganska fort ner när vi gör det.
Svårigheten är såklart att undvika att ”lura in” användaren i en videostart som den sedan överger. Speciellt när du som barn ofta har en begränsad skärmtid. Relevansen är nästan hela UX-upplevelsen i den här typen av katalogtjänster (där gränssnittet nästan helt reduceras till transit in till videoströmmar).
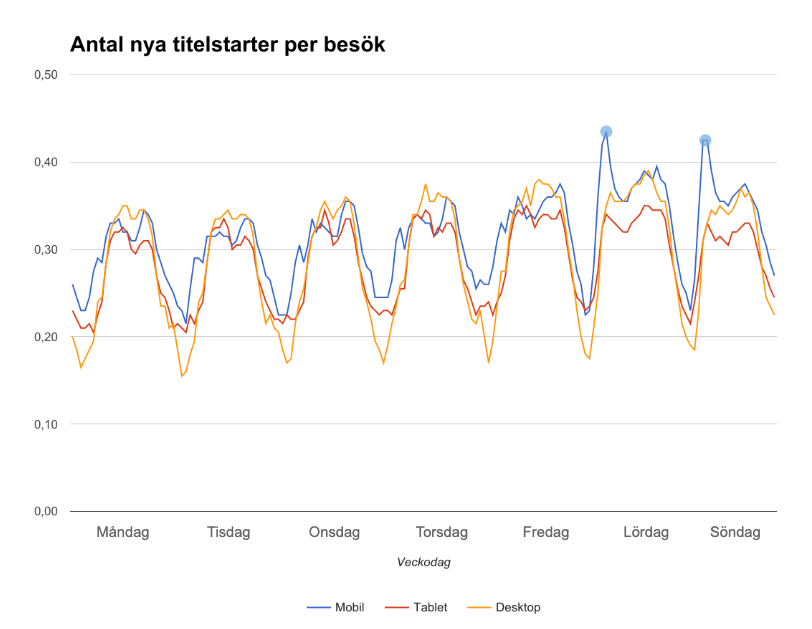
Det jag ser är att barn i större utsträckning konsumerar serier de sett innan (= låg risk) under vardagar medan de på lov och helger är mer benägna att utforska titlar de inte sett innan (mer skärmtid = kan ta högre risk). Under en typisk skolvecka peakar nytittning på lördag och söndag morgon mellan kl 6–8.
En inte allt för vågad gissning är att trötta småbarnsföräldrar vill sova ut.
Uppföljning av innehåll
Jag lägger lejonparten av min analystid på att följa upp innehåll på en rad olika sätt. Dels för att få bättre insikter om vilka enskilda titlar som skapar räckvidd och lojalitet, men också för att förstå större mönster som vilka ämnen, format, känslor, produktionsformer, etc som engagerar bäst.
På titelsnivå skapar jag en filtrerbar rapport i Google Data Studio som ger redaktörer, programinköpare och programutvecklare en översikt över hur väl en titel presterar. Bl.a. visar den:
- Hur konsumeras titeln?
- Hur korrelerar veckoräckvidd med publiceringstempo?
- Hur påverkar helt nytt innehåll och repriser räckvidd?
- Hur ser veckoåterkommandegraden ut generellt, och vid nytt innehåll?
- Hur ser completion rate ut vid kvalitetsstarter?
- Hur mycket värde skapar titeln i relation till liknande titlar?

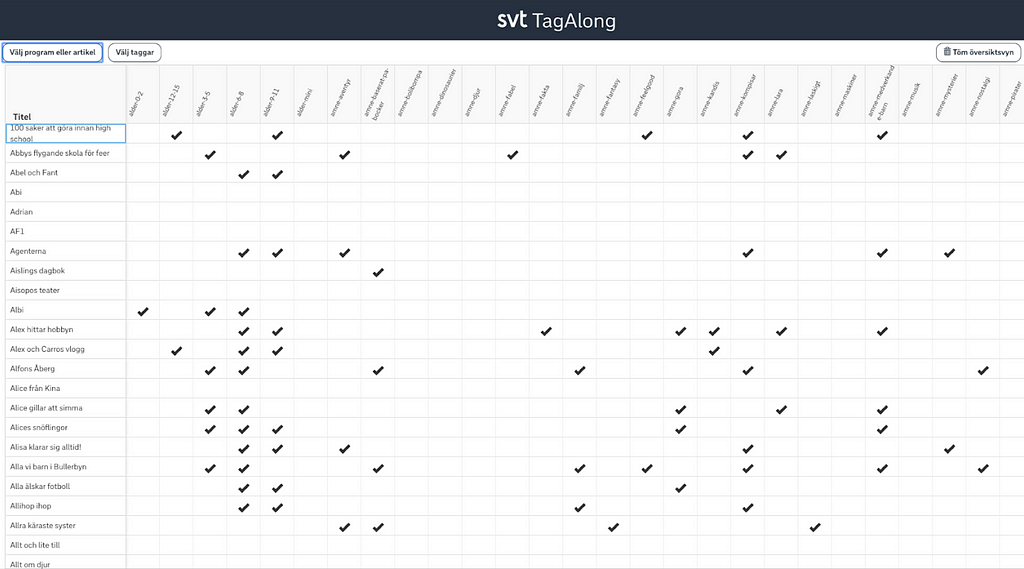
Taggning av innehåll
För att kunna filtrera och aggregera vettigt i analysen behöver innehållet taggas upp med metadata. Av de som bäst förstår innehållet samt hur innehållet tas fram och köps in.
Vilken metadata en väljer att ta med bör helt och hållet styras av hur inköps- och produktionsbesluten tas. Fall inte i fällan att tagga upp innehåll efter vad som är 100% rätt semantiskt (bibliotekarier är dock sjukt värdefulla i andra metadatasammanhang).
Tänk också på att verksamheter har sina egna sätt att ta beslut. Därför upplever jag att det ofta är dödfött att ta fram ett allövergripande taggsystem för samtliga verksamheter. Det är en lång, och ofta internpolitisk, process som kan leda till oprecisa taggar och avsaknad av viktig metadata. Vilket innebär sämre analys och beslut.
Exempel: köper du in barntitlar kanske du tar beslut efter kriterier som åldersgrupp i kombination med format. Jobbar du med dokumentärer kan det snarare vara berättarstil i kombination med ämne som är relevant.
Min approach har istället varit att ta fram olika metadatauppsättningar för olika verksamheter och sedan aggregera upp det som är viktigast till ett övergripande beslutssystem. Ju fler avdelningar jag hjälper med analysstöd, desto större och mer omfattande blir det övergripande systemet.
Taggning sker än så länge inte av sig själv (de få autotaggningsexperiment vi genomfört fungerar hittills mycket bättre på nyheter/artiklar).
Viktigt därför att kommunicera att taggningen kommer hjälpa till att lösa analys- och affärsproblem. Kvalitet på taggningen påverkar alltså hur väl underbyggda beslut en kan ta i framtiden.
Ytterligare en lärdom är ha separata taxonomier för “analystaggar” och taggar som används för att skapa listor och grupperingar gentemot användarna (“gränssnittstaggar”). Eller rättare sagt, taggar som används i gränssnittet kommer inte på långa vägar tillgodose analysbehovet.
Exempel: En programutvecklare vill undersöka hur väl småbarnsinnehåll presterar där huvudpersonen tittar rakt in i kameran jämfört med motsatsen. Relevant metdata för analys men knappast för ett gränssnitt. Eller tvärtom: Grännsnittstaggar som ”Spännande” (helt i betraktarens öga) och ”Baserad på böcker” (svårt att generalisera efter, då vissa böcker är obskyra och andra i Pippi Långstrump-klass) har klart begränsad analysnytta för mig.
Taggningen bör vävas in naturligt i redaktörernas process när en ny titel publiceras eller läggs in publiceringssystemet. En redaktion jag jobbar med vill helst ha en ping varje måndag, med en lista över vilka program som precis har publicerats och behöver taggas upp. Med direktlänk.
Då jag berikar vår beteendedata med metadata i en egen process är det inte avgörande att taggningen görs direkt när en ny titel har publicerats. Jag kan fortfarande berika historisk data bakåt. Att okeja segfärdig analystaggning är ytterligare ett skäl — speciellt i semestertider — till att ha olika taxonomier för gränssnitts- och analystaggar.
Filtrering
Jag bygger mina rapporter i Google Data Studio som erbjuder bra flexibilitet i att kustomisera filtrering. Vissa rapporter behöver sina egna unika filter. Förutom filtrering av exempelvis listor kan filtren dessutom användas för ren utforskning. Det är väl mest relevant när en följer upp en stor mängd titlar.
Exempel: undersök vad vi har för animerade titlar för 3–5 åringar som handlar om djur där en kille har huvudrollen. Eller kolla upp hur väl egenproducerade storbarnsdraman om relationer och kompisar presterar jämfört med inköpta dito från andra skandinaviska länder.
Nytt innehåll
Som jag tidigare skrev är det ett uttalat strategiskt mål att hålla räckviddskurvorna för de viktigaste segmenten så raka som möjligt under året.
Alla barn ska känna att vår tjänst är till för dem.
Det innebär att dessa målgrupper jämnt och kontinuerligt måste matas med innehåll. Helst lite mer och lite populärare innehåll för att fylla upp när skärmtid och utforskningsbenägenhet ökar. Alltså på lov och under helger.
Det finns självklart skillnader mellan våra åldersmålgrupper, men på ett generellt plan kan vi slå fast att:
- mängden nytt innehåll,
- mängden nya repriser, och
- mängden totalt innehåll
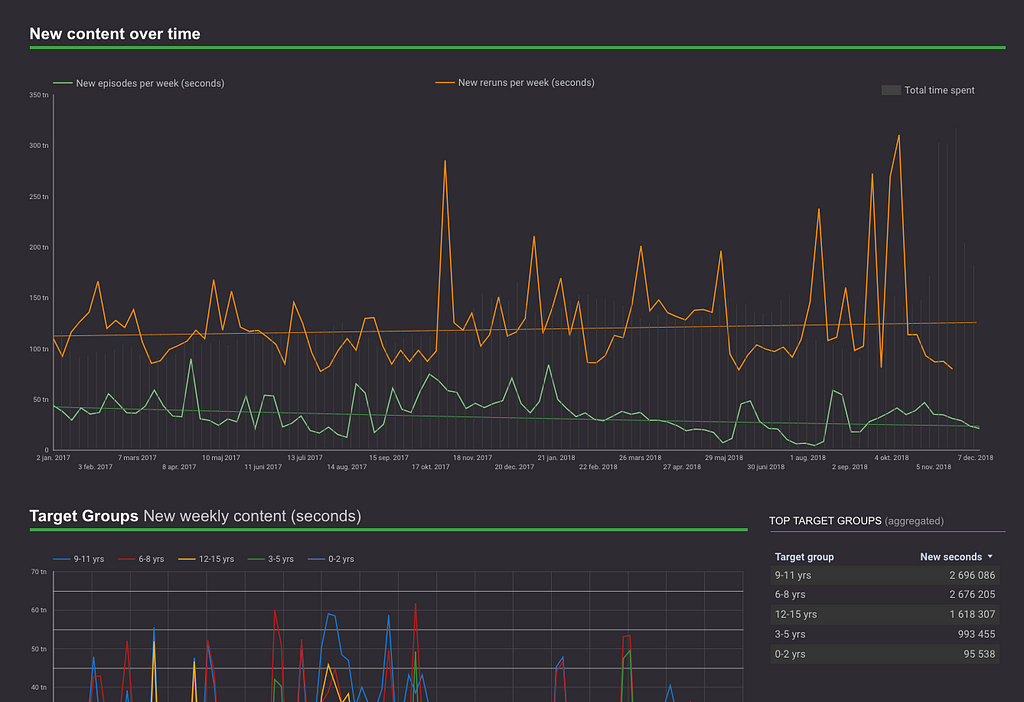
korrelerar högst med veckoräckvidd och veckoåterkommandegrad (i den ordningen). För vissa titlar är korrelationen mellan nytt innehåll och veckoräckvidd så hög som 0,90. Med ”nytt” menar jag innehåll som inte fanns i tjänsten föregående vecka.
Därför följer vi upp hur många episoder nytt innehåll, samt hur många minuter nytt innehåll vi släpper varje vecka. Givetvis filtreras detta också ner på målgrupps- och ämnesnivå för att identifiera luckor och onödiga spikar.
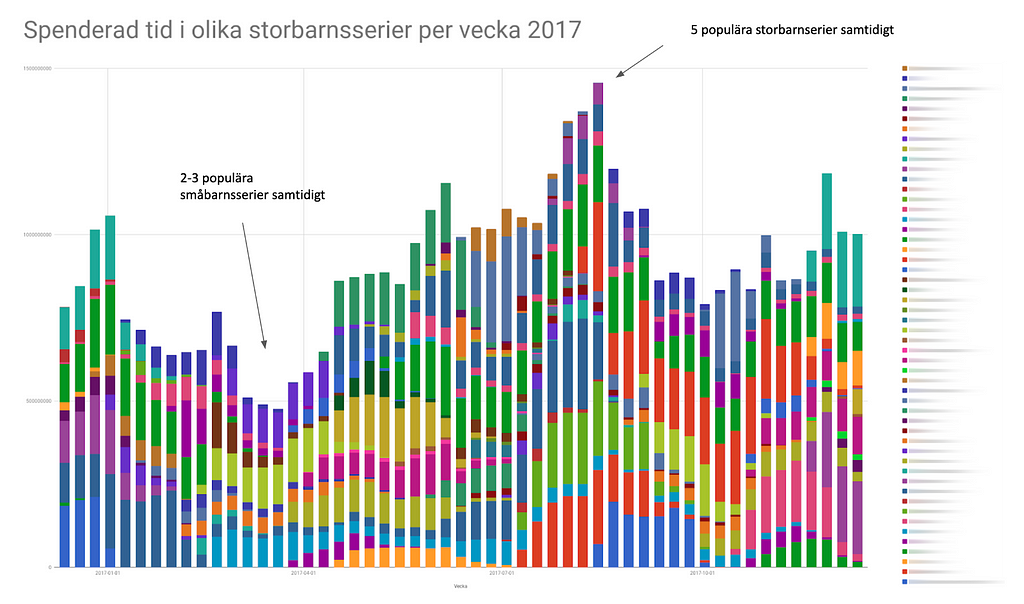
Då vi har en rätt tajt budget för innehåll, och när antalet tjänster som riktar sig mot samma målgrupp blir allt fler, kan en miss i publiceringen — t.ex. att vi sänder för många dramaserier parallellt tidigt på året — få betydande konsekvenser på genomsnittlig veckoräckvidd över helåret (vår viktigaste KPI).
Ämnen
Jag följer upp vilka ämnen som presterar bra respektive dåligt för att feedbacka in till de som jobbar med programutveckling och inköp.
Dels analyserar jag ämnestrender över tid, men jag gör också KPI-uträkningar för att se hur mycket värde titlar taggade med ett visst ämne i genomsnitt skapar.
För att göra det senare krävs tillräckligt många titlar inom ett ämne för att ens kunna generalisera med någon sånär träffsäkerhet.
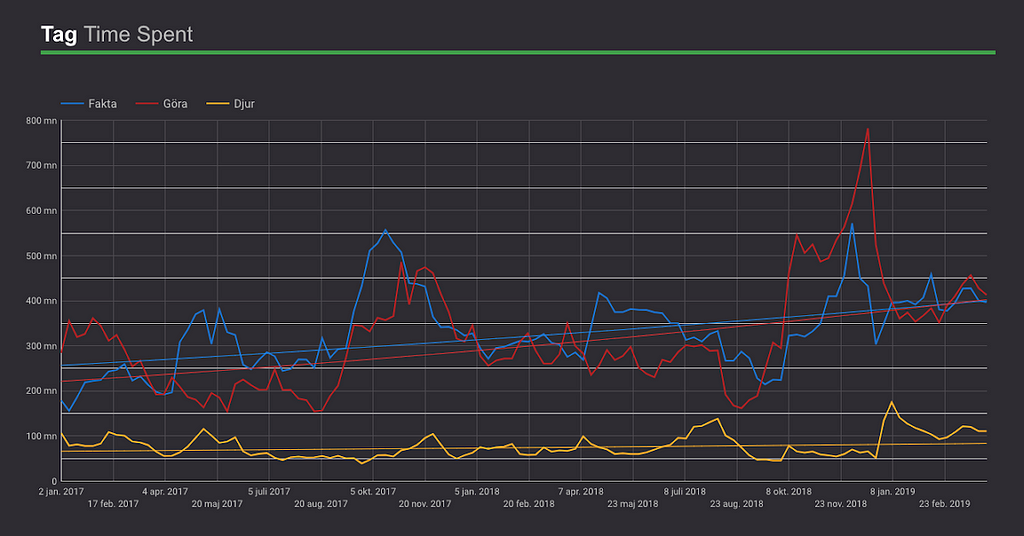
Dock tycker jag det är värdefullt att även ge input till programutvecklare att fortsätta ta fram innehåll inom ämnen med få titlar men som hittills presterar bra, säg ”dinosaurier” och ”robotar”. Fortsätt med titlar tills vi kan validera generaliseringen att ämnet bidrar med värde över genomsnittet.
Pedagogiskt tycker jag att ämnesuppföljningen fungerar utmärkt. Jag tycker det är extra givande och värdefullt att ifrågasätta gamla sanningar som att ”program med djur brukar gå bra”, eller ”föräldrar till småbarn gillar en pedagogisk och lärande vinkel”, etc.
Med den här uppföljningen kan jag tydligt visa att det t.ex. krävs i snitt 33 programtitlar innan en lyckas utveckla en titel taggad med ”djur” som blir populär. Samtidigt som vi har mycket högre hit rate på ”sci-fi”, ”kompisar” och ”fantasy”.
Förutom intern historisk data behövs extern trenddata från ex Google eller YouTube Trends i beslutsprocessen. Historik är en sak. Och saker förändras.
Framförallt använder jag Googles kunskapsgraf (som innehåller många barntitlar) med Google Trends för att se hur titlar vi funderar på att köpa in har gått i länder som har liknande beteende som i Sverige. Tänk Norge, Danmark, Nederländerna och Storbritannien.

Övrig metadata
Förutom ämnen följer jag detaljerat upp:
- Målgrupper (indelade efter ålder + familjetittning)
- Format (animation, drama, kortformat, etc)
- Huvudperson (kille, tjej, djur, sak, etc)
- Minoritetstitlar (ex teckentolkat, titlar på samiska, finska etc)
Metadata och målgrupper
Jag korskör metadata med målgrupper för att förstå vilken typ av innehåll som fungerar för vilken målgrupp. Av alla rapporter och underlag jag tar fram till mina stakeholders är nog den här den mest uppskattade. Det kanske är för att den ger en bra överblick?
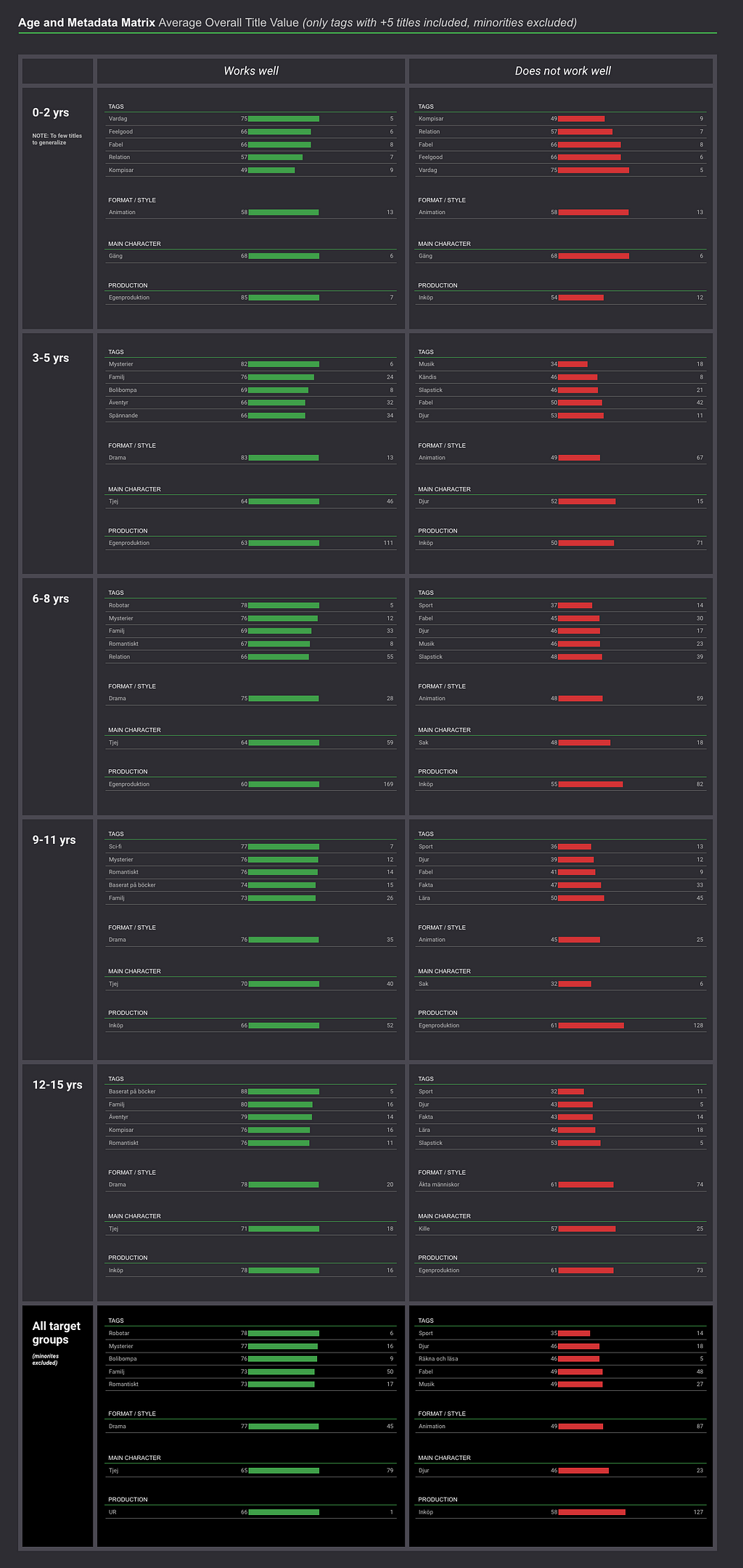
I den här rapporten kan en exempelvis se indikationer på att:
- Egenproducerat innehåll tenderar att fungera bäst för de yngsta målgrupperna.
- Relationer och drama verkar fungera bra redan från 5 års ålder.
- I nästan alla målgrupper är svårt att skapa värde med hjälp av musik-, sport- och djurprogram.
- Animerade titlar har svårt att skapa relativt värde redan från 3–5 års ålder.
Värde och rating
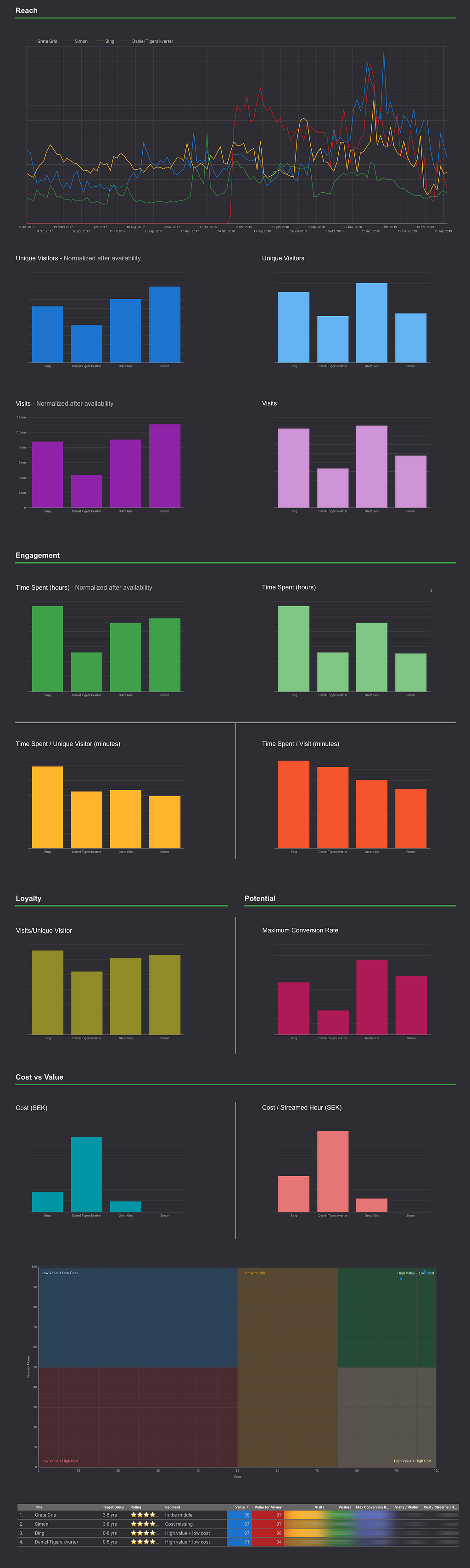
Hur sätter en egentligen ett rättvist “värde” på en titel? Så att det blir begripligt för andra än mig. Jag har testat flera modeller och till slut fastnat för en viktad modell där räckvidd, lojalitet, engagemang och potential (max-CR) ingår.
Så här ser viktningen ut i dagsläget:
- Räckvidd 55%
- Lojalitet: 30%
- Engagemang: 10%
- Potential: 5%
Räckvidd räknas ut av totalt antal unika besökare, unika besökare normaliserat efter tillgänglighet, antal besök samt antal besök normaliserat efter tillgänglighet.
Lojalitet består av besök/unik besökare, genomsnittlig veckoåterkommandegrad samt genomsnittlig veckoåterkommandegrad de veckor vi släpper nytt innehåll.
Engagemang räknas ut av total spenderad tid, total spenderad tid/unik besökare, completion rate, completion rate vid kvalitetsstarter (minst 30 sek tittning) samt completion rate normaliserat efter genomsnittlig episodlängd.
Potential är samma som maximal historisk veckokonverteringsgrad.
Viktigt att komma ihåg att data för titlar som är irrelevanta att återpublicera året runt (“säsongstitlar”) inte bör normaliseras. Det gäller exempelvis titlar som Sommarlov, jultitlar, samt titlar knutna till evenemang som idrott och nöje/Melodifestivalen.
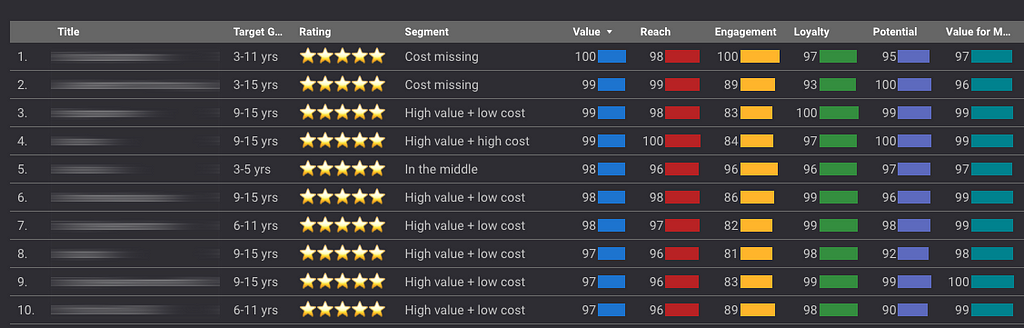
Alla titlar rangordnas sedan efter hur de presterar i de här fyra utvärderingskriterierna. Bäst placering ger högst poäng.
Det sista som händer är att de fyra rangordningarna summeras ihop viktat, samt räknas om till ett värdeindex där den bästa titeln får 100 poäng och den sämsta 0 poäng.
Det blir en relativ skala där framförallt titlar i botten och toppen identifieras och analyseras med extra intresse. Då värdeskalan är relativ finns det alltid något att förbättra och utvärdera.
För att göra det ännu enklare att förstå hur mycket värde en titel skapar sätts också stjärnor för varje titel, nästan som en normalfördelning. Topp 10% får 5 stjärnor, botten 15% får en stjärna, osv.
Värdesegment
Värde är en sak. Kostnad en annan. Det behövs lägereldstitlar som Julkalendern och Sommarlov som samlar våra målgrupper. Dessa titlar måste få kosta en rejäl slant då de skapar sån överlägsen lojalitet till vår tjänst och varumärke.
Det är en liten annan situation för innehållet som fyller upp katalogtjänsten, själva bulken. Där behöver vi köpa in och producera innehåll som skapar bra med värde per investerad krona. Och som samtidigt lever upp till public service-uppdraget.
Genom att berika beteendedata med licenskostnad, utvecklingskostnad och bearbetningskostnader kan jag räkna ut hur mycket det kostar att generera en strömmad timme för en titel.
Vi kan också aggregera upp kostnadsdata för vilken metadata vi vill, ex format, ämne, eller produktionstyp. Tänk dock på att du behöver hitta en avskrivningsmodell som passar just din organisation om exempelvis kostnaden togs för några år sedan och numera är begränsad vid en eventuell återpublicering.
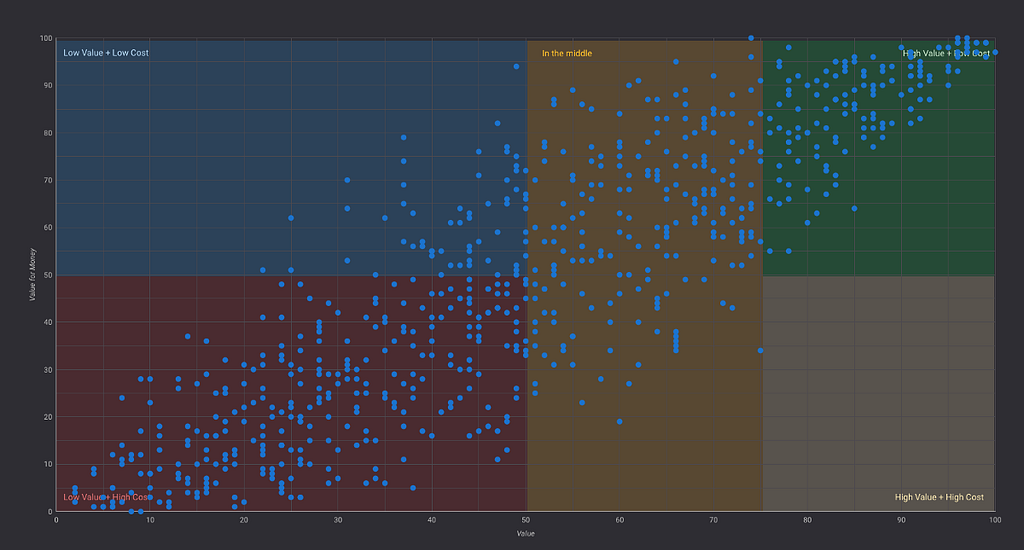
Förutom filtrerade prisvärdetopplistor tycker jag att värde/prisvärde-matriser är det mest effektiva sättet att visualisera den här kunskapen. Jag delar in matrisen i fem segment:
- Högpresterande och billigt (mest inköpta dramaserier)
- Högpresterande men dyrt (mest stora egenproduktioner)
- I mitten (blandat)
- Lågpresterande och billigt (nischat blandat innehåll, alternativt ej populärt innehåll)
- Lågpresterande men dyrt (oftast egenproduktioner som inte lyfter)
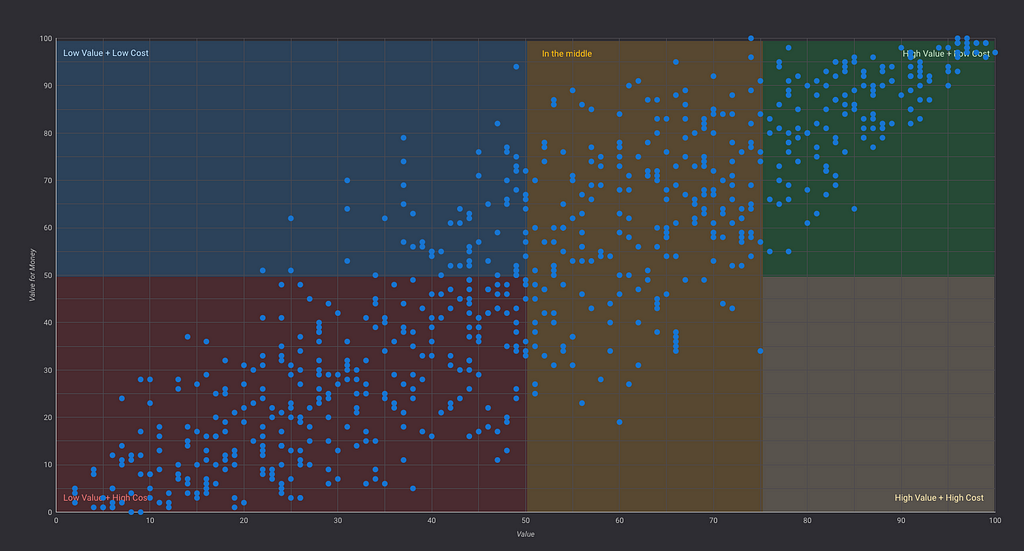
Självklart vill vi flytta våra titlar till höger i matrisen. Framförallt allra högst upp till höger. Det är dock viktigt att komma ihåg att innehåll som är lågpresterande kan fungera bra i ett gränssnitt som är väldigt personaliserat. Men det kan också vara så att innehållet inte fungerar alls för målgruppen. Då krävs ytterligare analys som resulterar i en rekommenderad action (se kommande avsnitt).
Topplistor
Jag använder listor för att enkelt kunna filtrera fram olika kluster av titlar som sedan jämförs med varandra. Typiska analyscase som kommer från verksamheten kan vara att utvärdera och rangordna titlar inom:
- Animerade serier för 0–5 år med kille i huvudrollen.
- Inköpt drama för 9–15 år som är taggat med antingen ”relationer” eller ”kompisar”.
- Alla egenproducerade titlar för de allra yngsta barnen 0–2 år.
Som jag tidigare nämnt är smarta filter på listor ett utmärkt sätt att utforska sitt utbud. Speciellt om en har en stor mängd titlar. Inte sällan leder den här typen av utforskning till användarinsikter, förbättringshypoteser och fördjupade analyser.
Head to head
Ett annat vanligt förekommande analysproblem för mig är att jämföra en mindre mängd utvalda titlar mot varandra. Det vanligaste är att ta beslut om vilka titlar en ska köpa in ytterligare en säsong av. Eller om det är värt att förlänga rättigheter.
Actions
Den sista delen av innehållsanalysen jag gör är att semi-automatiskt (snart automatiskt) ge förslag på actions på titelnivå. Nästan alla tidigare nämnda mätpunkter kastas in i en segmenteringsmodell som även inkluderar trenddata.
Titlarna hamnar i någon av åtta “actions-grupper” (inom sitt kluster):
- Ha kvar — bra räckvidd och lojalitet
- Ha kvar — bra räckvidd
- Ha kvar — bra lojalitet + ok räckvidd
- Ha kvar — lång spenderad tid + ok räckvidd
- Ha kvar — I mitten
- På gränsen — bör bidra med något annat (bidra med särskilt public service-värde, viktigt för minoriteter, strategiskt viktiga titlar, etc)
- Avveckla — dålig räckvidd
- Avveckla — dålig lojalitet + dålig räckvidd

Predicering
En kommande ambition är att bygga in mer automatiserad predicering i det här beslutsstödet. Dels för titlar, men också för målgrupper, ämnen och viktiga användarkluster.
Exempel på automatiserade pingar: “Dessa titlar överexponeras — de hittas ändå.” “Vi kommer sakna drama för 12–15-åringar i april-maj.” “Dessa titlar har för snabbt/långsamt publiceringstempo för optimal lojaltet till tjänsten.”
Vi behöver få till feedback och pingar till fem processer som är olika långa:
- Strategiarbete (12+ månaders feedbackloop)
- Egenproduktion (12+ månaders feedbackloop)
- Inköp (6–12 månaders feedbackloop)
- Publicering (3–6 månaders feedbackloop)
- Exponering (15 minuters feedbackloop — kan egentligen redan nu automatiseras)
Ju längre loop, desto tidigare behöver vi förslag på action.
Uppföljning av gränssnitt
Även om många A/B-test visar att de flesta gränssnittsförändringar vi gör (i den här typen av katalogtjänster) har begränsad KPI- och beteendepåverkan på lång sikt, följer vi givetvis upp alla justeringar vi gör. Anledningen är såklart att bygga validerad kunskap om användarnas beteende.
I princip alla releaser A/B-testas för att vi ska kunna identifiera risker som främst rör minskad lojalitet, men också för att veta exakt vilken effekt releasen gör innan vi släpper den till alla. Det kan vara en sådan enkel sak som en liten justering i popularitetsalgoritmen för att se hur det slår på ny- respektive omtittning. Eller en liten placeringsförändring av stängkrysset vid sökrutan. Påverkar det hittbarheten i sök eller ej?
Det överlägset lurigaste med att följa upp förändringar i gränssnitt och nya features är att förstå när förändringskurvan har stabiliserat sig. D.v.s. när kan en veta att förändringen skapat eller inte skapat hållbart värde?
Jag har märkt att då vi har en stor andel lojala användare, finns ibland en initial ökad benägenhet att testa nya features. På kort sikt kan det då se ut som att gränssnittsförändringar och nya funktioner verkar fungera bra, för att sedan långsamt tappa sin attraktion. Egentligen löste förändringen inget verkligt problem.
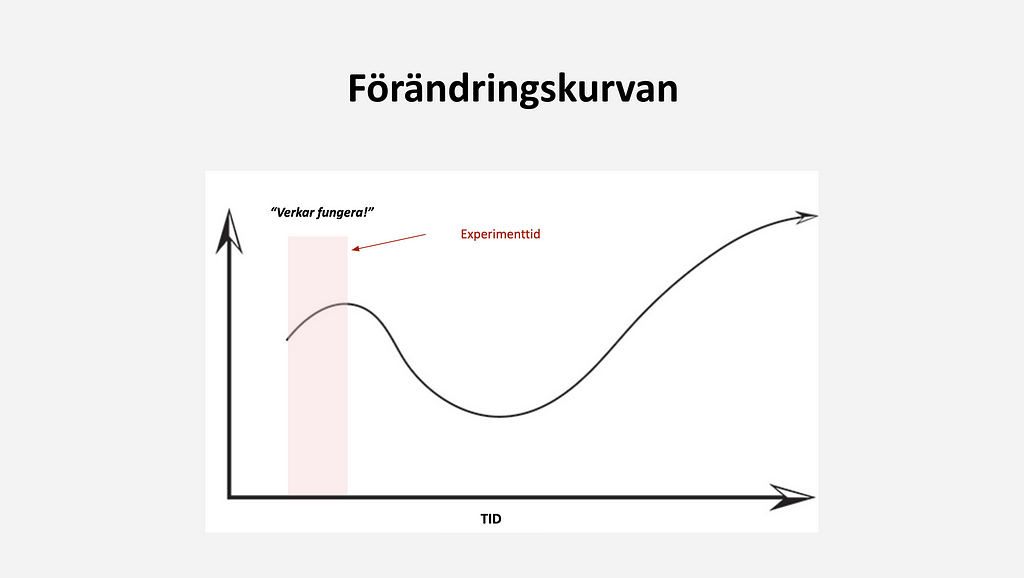
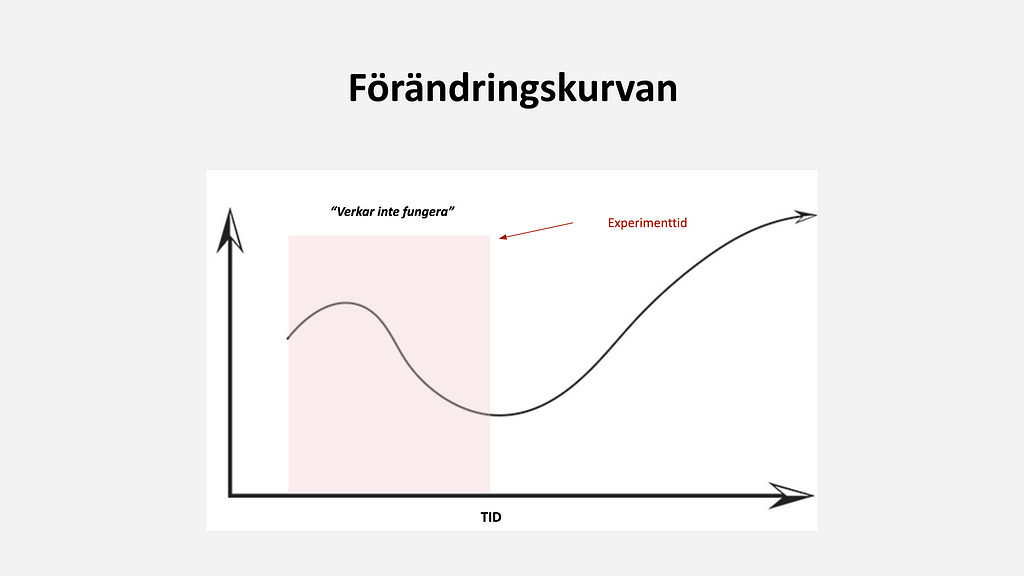
Viktiga mätpunkter som jag använder mig av för att förstå upplevt värde är lojalitet till funktionen, hur funktionen påverkar lojalitet till tjänsten i stort, spenderad tid i den nya kontexten, samt spenderad tid i tjänsten totalt. Allt detta mäts över tid och visualiseras för tydlighetens skull som ackumulerat medelvärde alternativt glidande medelvärde.
Det är också värt att notera att säsongsvariationer — som främst rör utbud och tillgänglig skärmtid — ofta påverkar resultat av A/B-test och uppföljning. Det är ingen idé att testa features som sedan ska fyllas med begränsat med innehåll, exempelvis storbarnsdrama under maj månad. Inte signifikativt. Inget riktigt test av idéns fulla potential.
Det var det, folks. Så jobbar jag numera med uppföljning av strömmande video för barn. Men det finns säkert tusen andra sätt.
Några kallar det för att jobba datadrivet. Själv skulle jag säga att jag bara hjälper duktiga specialister och team att göra ett vassare jobb, och lära sig validerat. Att ta mer insatta beslut. Att undvika waste och att korta ner feedbackloopar.
Kalla det för digital transformation om du vill, men i så fall en transformation underifrån och organiskt. Utan att någon ens yttrat termen.
Detta inlägg publicerades ursprungligen på Medium 26 augusti 2019.