Förra våren satt vårt team på den vanliga lunchrestaurangen utanför SVT-huset. Över fina burgare och ytterst mediokra bowls diskuterade vi huruvida stora språkmodeller skulle kunna använda engagemangsavvikelsedata och undertexter ihop. För att göra superkontextuella analyser över vad som fungerar bra respektive dåligt i tv-program.
Idag är det väl nästan exakt ett år senare.
Och för första gången har vi publicerat ett 100% automatiserat agentflöde som ger programutvecklare och projektledare en full blown djupanalys av hur senaste säsongen av programmet gick.
En styv vecka efter sista episod är publicerad.
På classic-tiden, när vi satt på den där lunchrestaurangen, skulle det kanske ta en erfaren innehållsanalytiker 40 h att göra en typisk ambitiös säsongsanalys. Det skulle bli en bra analys. Vi skulle pekat ut vilka målgrupper som träffades särskilt bra, kanske kommit med påpekanden om att det tidiga outrot skulle förkortas. Och kanske att vissa typer av sketcher och inslag har ovanligt hög avhoppningsfrekvens. Ja, ni förstår. Bra, bra men inte bäst.
Nu tar en analys 1-2h att köra. Genom ett helt automatiserat agentflöde. Men noga instruerat och kurerat.
En mild, balanserad och sansad analytiker — vilket jag är — skulle säkert uppskatta den upplevda skillnaden på det agentiska flödets output med den duktige innehållsanalytikerns dito ungefär så här.
- Helhetsnivå insikter: 5x bättre än en erfaren innehållsanalytiker
- Kvalitét på hypoteser och förbättringsförslag: 2x
- Hastigheten att ta fram en analys: 20x
- Mängden analyser: 50x (vi är uppe i 512 nu)
- Och priset, ja det kan ni säkert uppskatta själva
Så hur gör en? Utan att använda svart magi.
Exempel: Svenska nyheters vårsäsong 2026
Vi tar den precis avslutade säsongen av Svenska nyheter som exempel. En del siffror är slumpmässigt maskade. Men själva analysen delas i sin helhet så att du ska kunna följa resonemang.
Varning för longread, men håll ut.
(Varje gång du sammanfattar den här artikeln i en LLM-chatt dör både en kattunge och en fotbollsplan med träd i Amazonas.)

Så här gjorde vi
Även om vi började vårt MVP-utforskande med stora generativa promptar är det såklart ingen hållbar lösning i denna typ av kontext som ställer mycket höga krav på determenism, korrekthet och tydliga resonemang grundade i data.
Lösningen blev istället en orkestrerad multi-agent-pipeline med 23 specialiserade agenter som samarbetar i en strikt linjär kedja, med inbyggda QA-loopar, tillgång till AI-verktyg (s.k. “tools”) samt rigorösa dataintegritets- och formateringsregler.
Arkitekturen i stora drag
- 23 agenter i en sekventiell pipeline
- Primär språkmodell: Claude Opus 4.6 med thinking (extended reasoning), varierande effort (low/medium/high) och token-budgetar från 8 000 till 20 000+
- QA-modell: Gemini 3 Pro Preview med låg temperatur och strikta faktakontroll-instruktioner
- Efterbehandling: Dedikerade ihopslagnings-, formaterings- och “poleringsagenter”.
- Tools: Över 40 specialbyggda verktyg för SVT-data (utfall, episodanalyser, demografi, jämförelserymder, enhetskonsumtion, undertexter, bildanalys, metadata, etc) men också konkurrentpubliceringar, internetsök, väder m.fl.
Varje agent har ett extremt smalt och väldefinierat uppdrag, egna variabler (t.ex. {{previousOutput}}), egna tillgänglighetsregler till tools och egna strikta output-regler. Detta är nog nyckeln till varför resultatet blir så pass bra.
Nyckelagenter i flödet (några är utelämnade)
- Produktionskontext för programmet
- Drivkrafter för programmet
- Säsongsöversikt
- QA säsongsöversikt
- Detaljerad analys
- Målgruppsanalys
- QA målgruppsanalys
- Generella insikter
- QA generella insikter
- Planerings- och publiceringsanalys
- Marknadsanalys
- Hypoteser för nästa säsong
- Checklista nästa säsong
- Executive summary
- Sammanfogning
- Formatering
- CTA-punkter som lyfter analysens kärna
- Rubrik som ska locka till läsning
För att analysen ska fungera
Prompt-filosofi
Varje prompt är skriven som ett arbetspaket med:
- Tydlig roll
- Exakta regler för vad som är tillåtet och förbjudet
- Obligatoriska arbetsprocesser (t.ex. skapa intern tabell över siffror)
- Hårda dataintegritetsregler
- Mycket detaljerade markdown-mallar för outputkontroll
Vi har testat både traditionell instruktionsrik prompting samt mer öppen sokratisk prompting. Trenden för oss när det gäller vissa agenter går nog mer åt sokratisk prompting än mot mycket detaljerade instruktioner. Men det beror såklart på kontext och arbetsuppgift.
QA-systemet
Gemini-agenter har en enda uppgift: att underkänna vid faktiska fel, hallucinationer eller ogrundade generaliseringar. De får aldrig föreslå omformuleringar, bara godkänna eller underkänna. Max fyra försök per steg, annars fejlar hela workflowet.
Formateringsagenterna
Dessa är specialbyggda för att göra texten konsekvent och så “mänsklig” det bara går. De har en explicit lista som ersätter interna datatermer systematiskt. Funkar väl till 95%.
Thinking och token-budgetar
Claude Opus körs med thinking enabled och stora budgetar. Detta gör att agenterna verkligen resonerar djupt innan de svarar.
Detaljerad genomgång av rapporten och hur agenterna tar fram delarna
Nu följer en detaljerad beskrivning av de olika delarna i analysen, samt exempel på hur de ser ut.

Sammanfattning
Varför?
Sammanfattningen är den första och den mest lästa delen av analysen. Den ger en skarp, koncis överblick över säsongens viktigaste resultat: att det här är programmets starkaste onlinesäsong någonsin, att online överträffar broadcast, att ämnesval styr räckviddsvariation, att inledningarna är den svagaste punkten och att virala genomslag sänker färdigtittningen.
Vilken agent skapade detta?
Agent 14: Executive summary (Claude Opus 4.6, thinking medium, 14 k tokens).
Hur arbetade agenten?
Mer om detta senare men agenten får alla tidigare delanalyser (säsongsöversikt, detaljerad analys, målgruppsanalys, generella insikter, planeringsanalys och marknadsanalys) som input. Den instrueras att skapa en “koncis men innehållsrik executive summary” som lyfter de mest centrala observationerna utan att introducera nya slutsatser.
Den får strikta stilregler: internt analytiskt språk, inga överdrifter om de inte är väl underbyggda, procenttal med komma, och fokus på vad som är viktigast för någon som arbetar med programmet.
Svårigheten är att få agenten att välja få men rätt saker att lyfta istället för att summera en stor mängd text till obegripligt långa meningar för att klara sig inom sammanfattningens maxlängd.

Checklistor
Varför?
Efter sammanfattningen hittar läsaren oftast två praktiska checklistor: en för säsongen och en för episoder (om det finns flera episoder i säsongen). De är utformade för att direkt kunna användas av producenter, projektledare och inköpare för nästa veckas episod eller för nästa säsongplanering.
Dessa kommer tidigt i rapporten av två skäl: Dels för att vi som AI-orkestratörer (är det ett ord, ens?) snabbt kan se om resten av rapporten verkar okej då checklistans punkter är ett destillat av det absoslut viktigaste i rapporten. Men såklart också för att ge användaren konkreta förslag och förslag actions direkt utan långa bakgrundskapitel och resonemang.
Vilka agenter skapade detta?
Agent 13: Checklista nästa säsong + under-agent som trimmar checklista
Hur arbetade agenterna?
Agent 13 läser hela långa analysen och översätter alla insikter till konkreta, ja/nej-punkter med motiveringar. Den skapar checklistor på både säsongs- och episodnivå och grupperar dem logiskt (t.ex. “Inledning”, “Innehåll och sekvenser”, “Dramaturgisk uppbyggnad”).
En annan under-agent tar sedan resultatet och trimmar det: tar bort punkter som redan är uppfyllda i säsongen, slår ihop listor om de blir för korta, och säkerställer att checklistorna är koncisa och praktiskt användbara. Resultatet är de ganska rena, handlingsbara tabellerna du ser i rapporten.
Läsaren kan också skriva ut checklistorna direkt, högst upp i skärm-versionen av analysen.
Hypoteser och rekommendationer
Varför?
Det här avsnittet är det mest framåtblickande i analysen. Det innehåller fem till tio konkreta och motiverade hypoteser som “Öppna med spetsen, inte svepet”, “Det obekväma faktasegmentet”, “Klippfabriken”, “Pausvecka som strategisk förstärkare” m.fl.
Vilken agent skapade detta?
Agent 12: Hypoteser för nästa säsong (Claude Opus 4.6, thinking high, 20k tokens).
Hur arbetade agenten?
Agenten får hela analysen som input och instrueras att ta fram kreativa men realistiska hypoteser anpassade efter programmets storlek, uppskattad budget och ambition.
Den måste gå igenom en strikt arbetsprocess: generera ett brett urval idéer varav några radikala (10–20), kritiskt granska genomförbarhet, SVT:s uppdrag, redan gjorda saker, och sedan rangordna och skriva de bästa enligt en fast mall (Vad? Varför det kan fungera? Kritiska framgångsfaktorer). Den får också explicita förbud mot vissa typer av förslag.
Detta hypotesavsnitt har generellt fått ett mycket gott mottagande bland redaktioner och programutvecklare.



Ämnen och teman
Varför?
Vi analyserar ämnen och teman för att se om de verkar vara en viktig faktor bakom episodvariation och tittarbeteende. Inget unikt men vi ser i data att vissa ämnen har klart högre engagemangsnivåer än andra.
Ofta är det för tittaren vardagsnära eller konfrontativa ämnen, gärna med maktobalans, som engagerar. Ämnen som kan ge tittaren obehag på något sätt brukar konsekvent underprestera.
Just inom satir- och aktualitetsdrivna talkshows är det ibland inte formatet eller produktionskvaliteten som avgör framgång, utan just ämnesvalet och hur det hanteras satiriskt. Utan denna analys riskerar duktiga redaktioner att fortsätta med ämnen som de tror mycket på, men som inte håller tittarna kvar eller skapar genomslag.
Agenten instrueras såklart att alltid utgå från SVT:s uppdrag, även när det gäller rekommendationer kring ämnen.
I just den här analysen menar analysen (kanske lite för skarpt) att ämnesvalet är den enskilt viktigaste faktorn för hur utfallet påverkar utfallet. Rikspolitik med satirisk skärpa driver engagemang, medan lokala kuriositeter och nischade ämnen i inledningen tappar tittare. Aktualitet typ multiplicerar effekten.
Vilken agent skapade detta?
Agent 5: Detaljerad analys (Claude Opus 4.6, thinking high, 17 000 tokens).
Hur arbetade agenten?
En ganska komplex agent som gör en fullständig detaljerad analys. Agenten får instruktion att välja de mest relevanta aspekterna baserat på tidigare kontext och säsongsöversikt, och sedan genomföra en kort analys grundad i data, för varje aspekt.
Den använder episodanalyser (ett eget agentflöde likt detta men kortare), playback-data, avvikelsedata, internetsök, omvärldsanalys, spridning på sociala medier etc för att koppla ämnen till tittarbeteende.
Den har strikta regler om att inte upprepa information, att bara skriva om aspekter som har mätbar påverkan, och att uttrycka allt som tolkningar snarare än säkra orsaker.

Format och sekvenstyper
Varför?
En annan viktig aspekt som tenderar att påverka utfallet är vilka format- och sekvenstyper som engagerar extra bra och tvärtom. Vi har tagit fram en kontrollerad taxonomi av 60–70 typiska sekvenstyper som förekommer i tv-program.
Exempel på sekvenser kan vara: intervju, diskussion, sketch, monolog, på stan-intervju, outro, musikframträdande etc.
Vanliga mönster är att expertintervjuer (speciellt med experter som inte pratar svenska), långa expositioner samt vissa typer av sketcher kan leda till konsekventa avhopp i vissa typer av program. Samtidigt ser vi generellt höga engagemangstoppar vid heta, intima scener inom drama (chocken!), konfrontationer i samhällsprogram, etc. Men allt är såklart kontextuellt beroende på genre, episodlängd, aktualitet etc.
Här visar analysen vilka format som fungerar bäst just för Svenska nyheter: satirisk fördjupning med faktagrund är starkast, medan fältinslag med tunn premiss och monologinledningar med splittrat fokus är svagast.
Vilken agent skapade detta?
Samma agent som ovan: Agent 5.
Hur arbetade agenten?
Agenten fortsätter sitt arbete från föregående del och analyserar specifikt sekvenstyper, längd, placering och engagemang baserat på starka/svaga segment (värt en helt egen artikel hur vi räknar ut dessa) från episodanalyser.
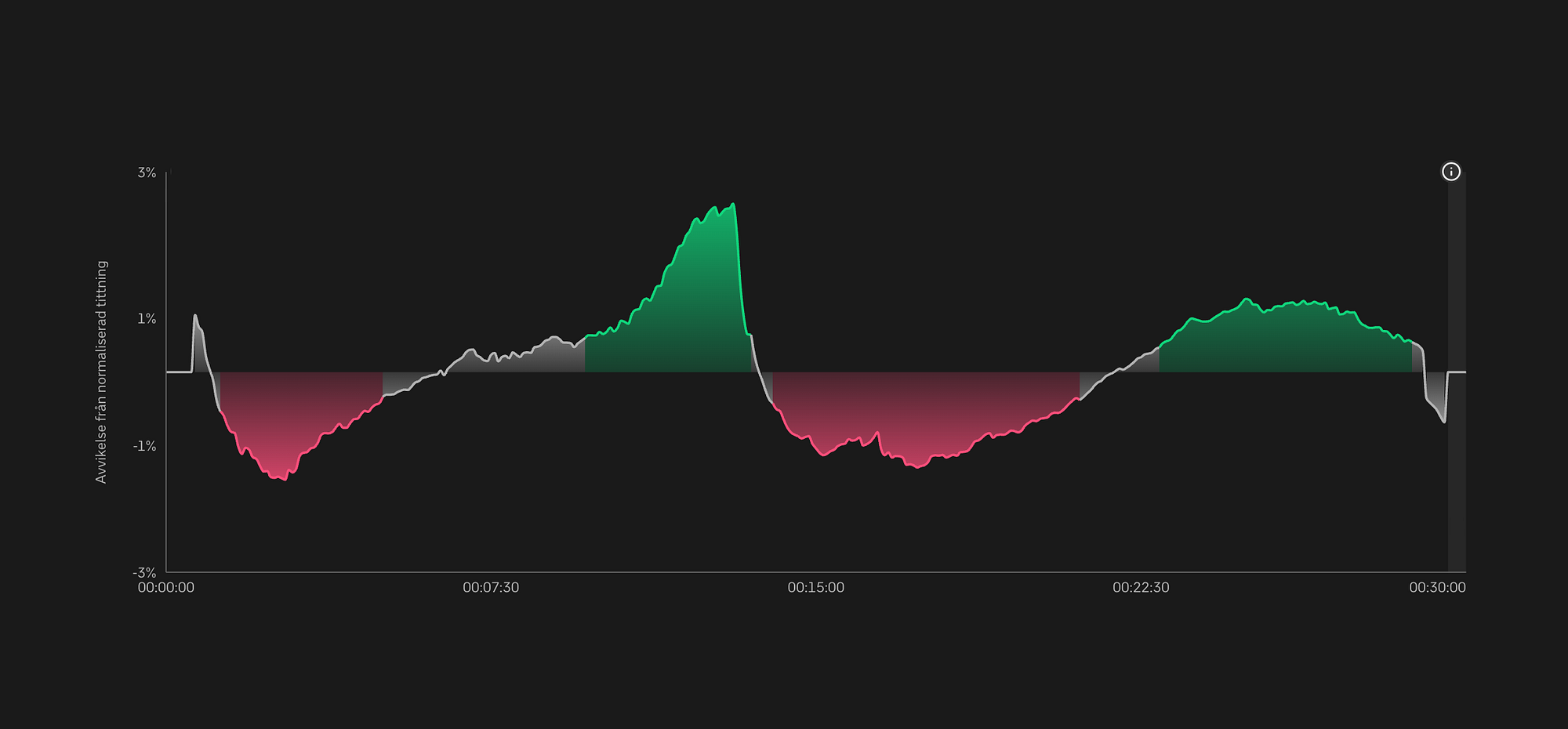
Identifierade starka och svaga segment i en episod baserat på omtittning, avhopp och spolning.
Den identifierar tydliga mönster över säsongen och kopplar dem till tittarengagemanget.

Genomslag och spridning
Varför?
Som programutvecklare eller kommunikatör vill du ofta veta hur programmet eller enskilda episoder har fått någon större spridning i sociala medier eller artiklar och genomslag i gammelmedia. Spridning har i en del fall stor utfallspåverkan på enskilda episoder, och även säsonger.
Avsnittet från exemplet visar hur viralt genomslag (t.ex. GW-äppelaktionen) breddar publiken men sänker färdigtittningen, och hur avsnitt utan medial spridning har mer stabila färdigtittningsmönster.
Vilken agent skapade detta?
Återigen Agent 5.
Hur arbetade agenten?
Agenten använder tools för att hämta information om mediebevakning och kopplar resultatet till tittardata. Här drar den slutsatsen att extern spridning är en hävstång, men också att den drar in en bredare och mindre engagerad publik.
Kanske inte superhög höjd på denna, ganska generella, slutsats.
Inledningar
Varför?
Inledningar av de flesta program är särskilt viktiga då tidiga avhopp påverkar resterande ratingen av episoden och i vissa fall ratingen för hela säsonger. Detta är främst typiskt för drama- och humorserier men även dokumentärer och talkshows har stor nytta av detaljerad analys av dropoff under inledningar.
Vilken agent skapade detta?
Agent 5 igen.
Hur arbetade agenten?
Agenten har en specifik instruktion att analysera hur väl de första minuterna fångar tittarna, med fokus på s.k. kvarhållningspunkter, där vi matematiskt räknar ut att episoden har “fångat” sina tittare, alltså där avhoppningen planar ut.
Men även hur det detaljerade mönstret ser ut för avhoppningen samt i jämförelse med andra episoder. Den använder playback-data och episodanalyser (också värt en egen artikel hur det agentflödet ser ut).

Berättande och tempo
Varför?
Detta avsnitt är viktigt för många typer av program; talkshows, dokumentärer, reality för att nämna några.
Föga förvånande går trenden online mot ett allt kortare attention span. Detta eftersom den övervägande delen av skärmtiden tillbringas i sociala medier och YouTube, vilket i sin tur sätter konventionen för allt rörligt innehåll.
Här är det dock stor skillnad mellan framåtlutat tittande (mobila enheter med typ noll barriär för att hoppa 15 sekunder vid långsamt tempo) och bakåtlutat tittande (storskärm med större tröskel för att spola/hoppa av — kämpa att ta sig till fjärrkontrollen!).
Vilken agent skapade detta?
Agent 5 återigen.
Hur arbetade agenten?
Agenten analyserar tempo och dramaturgi baserat på avvikelsedata i episoden jämfört med förväntat beteende (på sekundvivå) samt episodanalyser och kopplar det till tittarbeteende.
Prioriterad målgrupp
Varför?
De flesta program som produceras eller köps in har en utpekad åldersmålgrupp och ofta, om programmet har en större ambition och budget, finns det ett målgruppsmål kopplat till programmet. Finns det ingen utpekad målgrupp faller agenten tillbaka på den generellt prioriterade målgruppen för SVT (och för typ alla andra streamingplattformar på den Svenska marknaden): 20–44 år.
Avsnittet konstaterar att säsongen har en positiv målgruppsavvikelse i 30–44 år online, men att den är måttlig jämfört med topptitlar inom humor.
Vilken agent skapade detta?
Agent 6: Målgruppsanalys (Claude Opus 4.6, thinking medium, 14000 tokens).
Hur arbetade agenten?
Agenten har mycket strikta regler kring målgruppsvalidering och att bara lyfta avvikelser som både är procentuellt stora och har tillräcklig volym.

Episodvariation målgrupper
Varför?
Det är vanligt med utfallsvariation mellan episoder även inom målgrupper och viktigt att förstå varför det sker. I denna typ av program — samt bredare talkshows och vissa nyhetsprogram — kan gäst-, ämnes- och viral spridning ha betydande påverkan på vilka målgrupper som nås extra bra.
Vilken agent skapade detta?
Agent 6 återigen.
Hur arbetade agenten?
Agenten skapar interna tabeller för att rangordna avvikelser och lyfter bara de mest betydande insikterna.I detta fall endast en.
Kön
Varför?
Kön är också en intressant aspekt även på en sådan granulär nivå som episoder. Redaktioner för t.ex. nyhets- och talkshow-program vill veta vilka ämnen och gäster som engagerar män respektive kvinnor.
Exempel Ekonomibyrån: Män verkar generellt konsumera ekonomiprogram som behandlar ämnen som rör börsen och investeringar mycket, medan kvinnor tenderar att engageras mer av bostads- och plånboksfrågor. Vill Ekonomibyrån nå yngre män? Gör ett avsnitt om krypto. Vill de nå yngre kvinnor? Gör ett avsnitt om hälso- och wellness-industrin.
Här nämner analysen att män överindexerar online medan kvinnor underindexerar, ett mönster som är ganska typiskt för satirprogram med samhälls- och politikfokus.
Modellen använder dels utfall från jämförelserymderna humor, talkshow och samhälle, men svarar också baserat på hur den är tränad på stora mängder global data.
Vilken agent skapade detta?
Agent 6 igen.
Hur arbetade agenten?
På samma sätt som tidigare tar agenten fram interna tabeller och lyfter endast större avvikelser i kombination med en viss nivå av konsumtion.
Lojalitet och kvarhållning
Varför?
Vissa typer av program — som drama- och dokumentärserier — har ofta ett naturligt, kontinuerligt men gradvis avtagande tapp. Talkshows däremot tenderar att variera betydligt mer, där kvarhållningen påverkas tydligt av faktorer som ämnesval, gäster, aktualitet och vilken dag avsnittet publiceras.
I denna analys hittar agenten inget som sticker ut utan konstaterar att säsongens kvarhållning är 73,1%. Premiären lockar brett, men det finns ett visst tapp mot slutet.
Vilken agent skapade detta?
Agent 8: Generella insikter.
Hur arbetade agenten?
Agenten drar bredare lärdomar utifrån hela analysen och fokuserar på mönster över hur säsongen utvecklades.
Färdigtittning och avhoppsmönster
Varför?
Vi analyserar färdigtittning och avhoppsmönster för att förstå hur väl programmet lyckas konvertera nyfikna startare till fullständiga tittare, en av de mest kritiska KPI:erna för långsiktig lojalitet och värde för SVT Play.
Ibland inom bl.a. talkshows och humor kan ett högt initialt intresse (stark premiär, viral spridning) skapa en falsk känsla av framgång medan den faktiska genomtittningen minskar. Men ofta är det tvärtom, att ju fler som hoppar av, desto mer lojal och “färdigtittande” publik får programmet. Den lojala kärnan.
Här visar analysen att färdigtittningen landar på stabila 61,6% i snitt för säsongen, med relativt liten spridning mellan avsnitt, utom vid virala avsnitt. Avsnitt 6 (GW/äppelaktionen) hade säsongens lägsta färdigtittning på 56,7% trots näst högst onlinerating, vilket tydligt indikerar att extern spridning lockar en bredare men mindre engagerad publik som inte stannar kvar. Avsnitt utan medial spridning uppvisar däremot mer stabila och högre färdigtittningsmönster.
Vilken agent skapade detta?
Agent 8 igen.
Hur arbetade agenten?
Agenten läser hela kedjan av tidigare analyser (inklusive episodanalyser och playback-data) och drar bredare, mönsterbaserade slutsatser om lojalitet och tittarbeteende över säsongen.

Vad har engagerat tittarna mest?
Varför?
En av de absolut mest intressanta delarna av analysen. Här kollar vi på vilka segment i serien som engagerar mest. Omtittning av sekvenser samt mycket låg avhoppningsgrad signalerar lite förenklat högt tittarengagemang.
Denna kunskap kan direkt användas för att prioritera innehåll samt sekvenstyper i nästa säsong. Eller nästa vecka om en gör program som går att påverka mellan publiceringarna.
Inom den här typen av program är det inte alltid det ”roligaste” eller mest kända ämnet som vinner, utan kombinationen av aktualitet, dramaturgi och en tydlig satirisk udd.
Här visar analysen att de starkaste segmenten under säsongen delar tre tydliga egenskaper: politiskt aktuella ämnen med högt nyhetsvärde, satirisk avslöjande av hyckleri eller absurditet, samt en tydlig dramaturgisk uppbyggnad där skämtet eskalerar och kulminerar.
Vilken agent skapade detta?
Agent 8 återigen.
Hur arbetade agenten?
Agenten identifierar de mest framträdande positiva mönstren genom att systematiskt jämföra episodanalyser, avvikelsedata och starka/svaga segment.
Vad har engagerat tittarna minst?
Varför?
Vi gör naturligtvis en liknande analys för att lära oss vad vi ska undvika nästa säsong.
Analysen visar här att de svagare segmenten är påfallande likartade konstruerade: inledande nyhetssvep, fältinslag med tunn premiss eller utdragna sketcher utan 100% tydlig nyhetskoppling. Dessa delar tenderar att ligga tidigt i avsnittet och orsakar både lågt engagemang och tidiga avhopp.
Vilken agent skapade detta?
Agent 8 igen.
Hur arbetade agenten?
Agenten lyfter de återkommande negativa mönstren genom att korsreferera episodanalyser och playback-data för att skapa en ”undvik-lista” för redaktionen.

Antal episoder
Varför?
Vi analyserar optimalt antal episoder för att hitta den sweet spot där räckvidd maximeras utan att lojaliteten och färdigtittningen sjunker för mycket mot säsongens slut.
Ofta inom veckovisa satir- och aktualitetsprogram leder för många avsnitt till trötthet hos både publik och redaktion, medan för få avsnitt ger för låg total räckvidd.
Analysen här visar att programmet historiskt pendlat mellan 10 och 15 avsnitt och att de senaste fyra säsongerna (S14 — S17) pekar på att 12 avsnitt är ett väl avvägt antal: det ger bra total räckvidd samtidigt som ratingen inte sjunker alltför mycket i slutet av säsongen.
Vilken agent skapade detta?
Agent 10: Planerings- och publiceringsanalys.
Hur arbetade agenten?
Agenten jämför historiska data, säsongstrender och externa faktorer och drar konkreta, kvantitativa underbyggda slutsatser.

Avsnittslängd
Varför?
Vi analyserar avsnittslängd för att säkerställa att längden matchar tittarnas faktiska beteende och optimerar både engagemang och färdigtittning. Inom den här typen av program som kombinerar humor med samhällsdebatt är 30 minuter en etablerad längd i Sverige, men det är inte självklart att den alltid är optimal. Som tidigare nämnt ser vi också en generell ökad skillnad i beteende mellan framåtlutat (mobila, personliga enheter) och bakåtlutat (broadcast och storskärm) beteende.
Analysen här visar att 30 minuter förmodligen fungerar utmärkt och bör behållas: färdigtittningen ligger stabilt kring 61,6% och engagemanget är jämnt fördelat över avsnittet utan tydliga tapp vid längre längd.
Vilken agent skapade detta?
Agent 10 igen.
Hur arbetade agenten?
Agenten analyserar färdigtittning, playback-data och engagemang i relation till episodernalängd och drar rekommendationer baserat på faktisk tittardata.
Publiceringsmodell
Varför?
Vi analyserar publiceringsmodell (box när alla avsnitt släpps direkt vs veckovis) för att hitta den strategi som bäst matchar programmets aktualitetsdrivna natur och tittarnas vanor.
Hur en taktiskt väljer att publicera avsnitten kan ibland ha stor påverkan på balansen mellan programmets rating och dess bidrag till veckoräckvidden. Vid box-publiceringar tenderar ratingen att gynnas på bekostnad av räckviddsbidraget, medan det blir tvärtom vid veckovis publicering — exempelvis med ett avsnitt per vecka.
Detta är särkilt svårt, och viktigt, t.ex. vid förstasäsonger av dramaserier där det kan vara svårt att uppskatta räckvidd och rating på förhand.
Exempel: En oväntad dramasuccé som box-publicerats wastar väldigt mycket bidrag till veckoräckvidd jämfört med om den veckopublicerats.
Analysen visar att veckovis publicering på fredagar är den rätta modellen för ett aktualitetsdrivet satirformat som Svenska nyheter: det ger kontinuerlig närvaro, bra räckvidd och matchar tittarnas veckovisa beteende bättre än en box-release. Ganska självklart. Men inte för alla typer av program.
Vilken agent skapade detta?
Agent 10 igen.
Hur arbetade agenten?
Agenten väger box mot veckovis, tar hänsyn till genre och tittarbeteende och ger en tydlig rekommendation.
Timing
Varför?
Vi analyserar timing (premiärvecka, pausvecka, hösts- eller vår etc) för att maximera räckvidd och minimera negativa externa faktorer som högtider och konkurrens. När det gäller stora underhållnings- och samhällsprogram kan fel tajming i publiceringen kosta hundratusentals tittare. Tänk större helgunderhållningssatsningar.
Den här analysen ger konkreta rekommendationer kring premiärvecka, pausvecka vid påsk och höststart i slutet av september för att undvika påskdipp och utnyttja en potentiell nyhetstörst under hösten efter sommarledigheten (och riksdagsval).
Vilken agent skapade detta?
Agent 10 igen.
Hur arbetade agenten?
Agenten tar hänsyn till högtider, historiska resultat och konkurrensläge och levererar praktiska tidplaneringsråd.
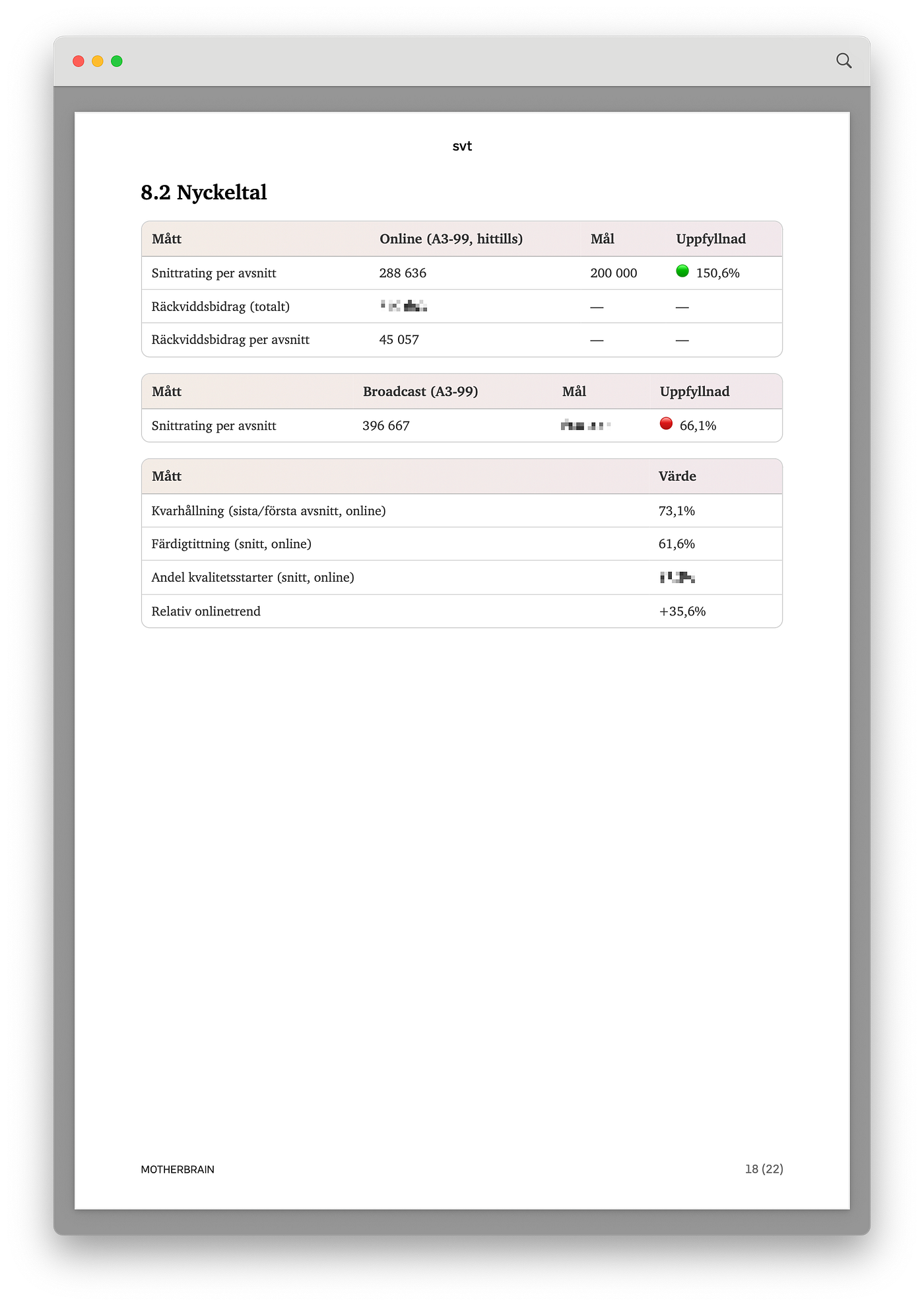
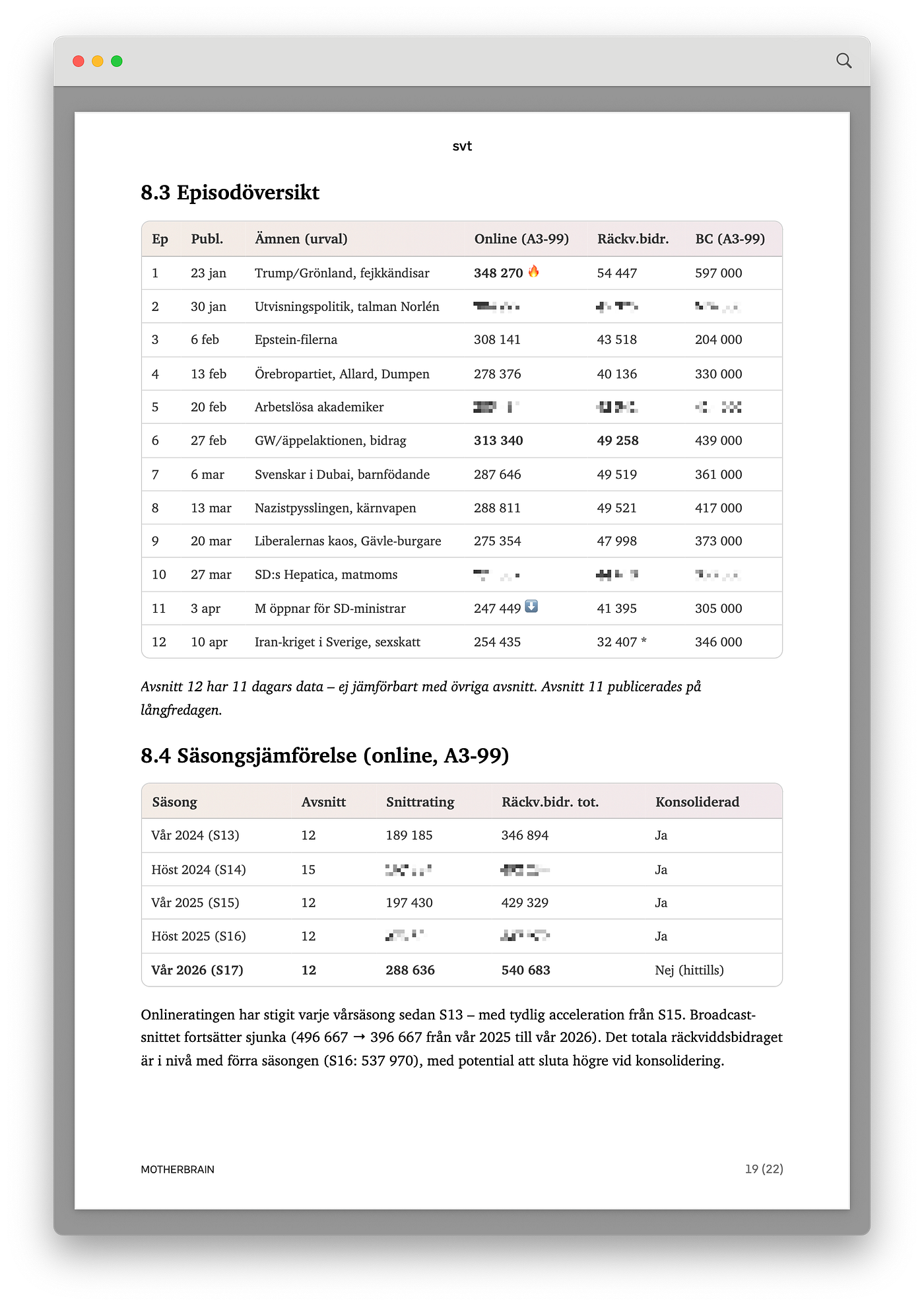
Säsongsöversikt
Varför?
Vi inkluderar en fullständig säsongsöversikt för att ge alla läsare — från programchef till analytiker — en gemensam, faktabaserad grund att stå på innan de går in i de mer tolkande delarna. Utan denna översikt blir resten av analysen svår att förankra i verklig data.
Tidigare låg denna del tidigare i rapporten, med nackdelen att det tog tid att komma till mer konkreta råd och rekommendationer.
Denna del visar tabeller med data, vilket de flesta andra delarna i analysen hoppar över för att istället resonera.
Analysen ger en klassisk översikt med metadata, nyckeltal (bland annat 73,1% kvarhållning, 61,6% färdigtittning, +35,6% relativ onlinetrend), episodtabell och jämförelse med tidigare säsonger.
Vilken agent skapade detta?
Agent 3: Säsongsöversikt.
Hur arbetade agenten?
En av de mest datahungriga agenterna i hela pipelinen som hämtar, konsoliderar och presenterar alla rådata som grund för resten av analysen.

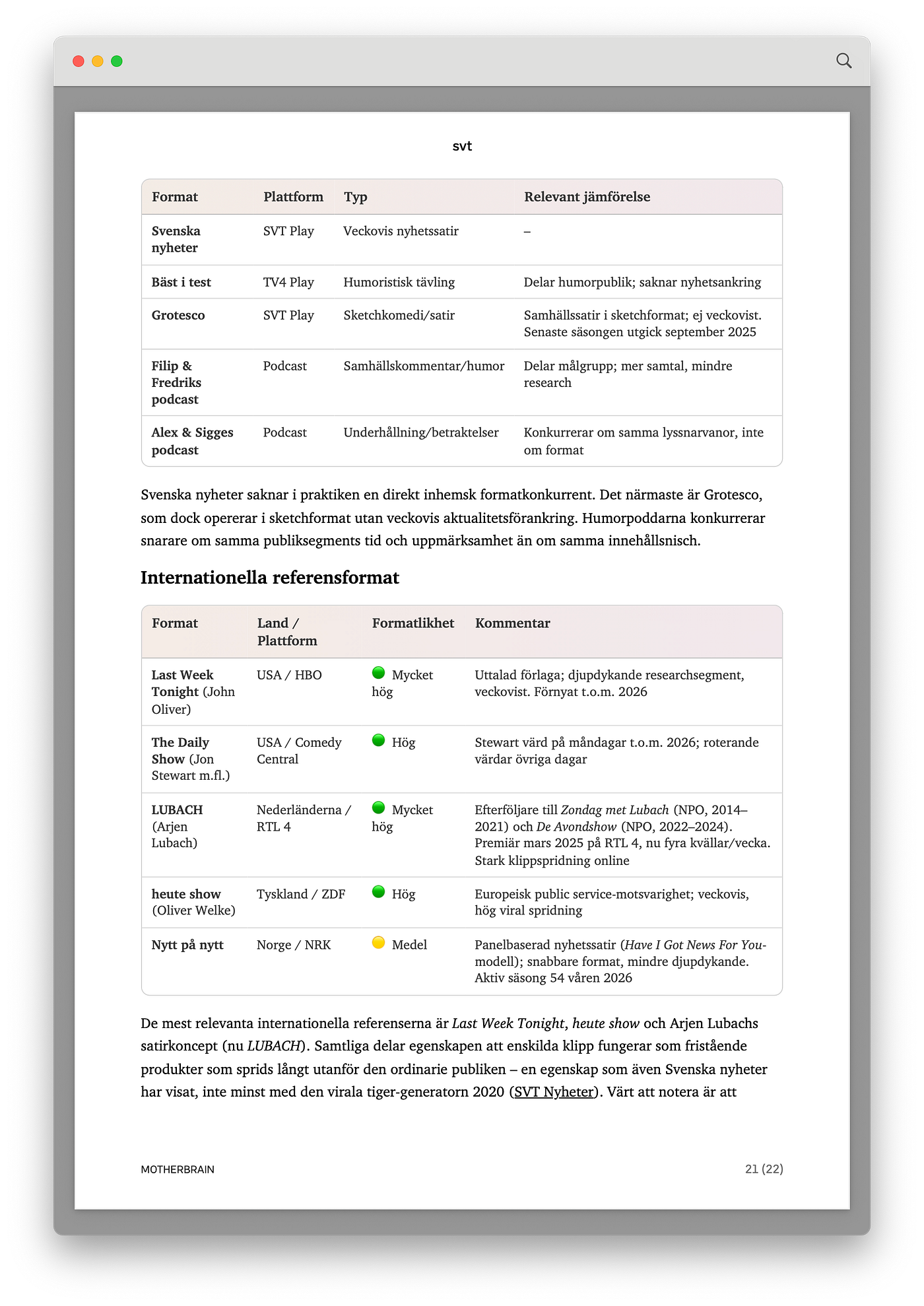
Marknadsanalys
Varför?
Vi lägger med en avslutande marknadsanalys i appendix för att placera Svenska nyheter i ett större svenskt och internationellt sammanhang, något som ger en bättre grund när programledning och programchefer ska fatta strategiska beslut om formatets framtid och positionering.
Dessa analyser brukar också ge en del idéer till inspiration på en mer taktisk nivå.
Analysen ger en gedigen kartläggning av svenska och internationella jämförbara format samt en tydlig positioneringsanalys.
Vilken agent skapade detta?
Agent 11: Marknadsanalys.
Hur arbetade agenten?
Är egentligen två agenter där den ena kartlägger och samlar in jämförelsematerial, medan den andra granskar, korrigerar och höjer precisionen för att säkerställa hög kvalitet i slutresultatet.


Summering och lärdomar
För exakt ett år sedan satt vi och pratade om att språkmodeller borde kunna göra det här. Idag har vi kört exakt 512 (yay!) säsongsanalyser i detta format. Och fortsätter att beta av historiska säsonger.
Några lärdomar efter att ha byggt, testat, kört om och itererat på flödet under ett halvår i produktion:
- Specialisering slår generalisering med hästlängder. En enda stor, smart prompt ger hyfsade resultat. 23 extremt smala, väldefinierade agenter med egna tools, egna variabler och egna regler ger resultat som är bättre än en erfaren analytiker. Framförallt är helheten långt mycket bättre.
- QA-loopar är det som gör systemet möjligt och trovärdigt. Utan kvalitetsagenter som bara får underkänna hade vi aldrig vågat släppa analyserna till redaktioner och programutvecklare. Möjligen att vi går mot att vara lite mer generösa kring hur många försök dessa agenter får på sig innan de fejlar hela flödet.
- Dataintegritet måste vara en icke förhandlingsbar regel. “Skriv aldrig en siffra från minnet” och “skapa intern tabell innan du skriver” är nu hårdkodat i nästan varje prompt. Detta har förmodligen räddat oss från hundratals potentiella hallucinationer.
- Thinking + stora token-budgetar är en game changer. När vi började köra modellerna med utökat resonerande och upp mot 20k tokens började agenterna plötsligt resonera som riktigt bra analytiker istället för att bara parafrasera data.
- Tools är inte ett tillägg, de är kärnan i allt. Utan tillgång till episodanalyser, playback-data på sekundnivå, avvikelsedata, internetsök och mediebevakning hade detaljanalyserna blivit ytliga. Verktygen gör att systemet faktiskt vet vad det pratar om. Här är vi bara i början och kostnaden för att skapa nya tools är försvinnande liten (finns dock annan intruktions,- och balanseringsproblematik med många tools)
- Formatering och terminologi är inte bara kosmetika. De sista formateringsagenterna som systematiskt ersätter “targetGroup” med “målgrupp”, “co90” med “konsoliderad” osv. gör att rapporten känns som något en människa skrivit, inte som AI-generiskt.
- Hastigheten förändrar allt. När en analys tar 2 timmar istället för 40 går det plötsligt att göra analyser på alla program, inte bara de stora. Det förändrar hela beslutsprocessen på SVT från “vi har inte råd att analysera det” till “vi har redan analysen”. Även för minoritetsprogram och supernischade inköpta dokumentärer.
- Människan är fortfarande nödvändig, men på en helt annan nivå. Vi har gått från att göra analyserna till att granska, prioritera och agera på dem. Visst, det är mer en strategisk roll nu. Men har det blivit roligare? Det ligger fortfarande i korten.
Mycket stor användning och beslutsunderlag redan nu
Som alla vet finns det ett mycket begränsat värde att ta fram rapporter, analyser eller dashboards om de inte används för att ta beslut.
På SVT finns det i runda slängar 1 000 personer som tar beslut som rör innehållet. Allt från klippare till programchef.
Själva BI-verktyget vi byggt — Motherbrain — hade 420 unika aktiva användare förra veckan. Tänk en organisation där 42% av de anställda i snitt använder traditionella BI-rapporter som PowerBI eller Tableau. Det är en stor succé redan innan de AI-stödda analyserna har börjat rullas ut.
Efter en månad av AI-stödda säsongsanalyser har vi i snitt 44 unika aktiva användare per vecka som läser igenom en säsongsanalys.
Och betygen på analyserna är klart över mål hittills:
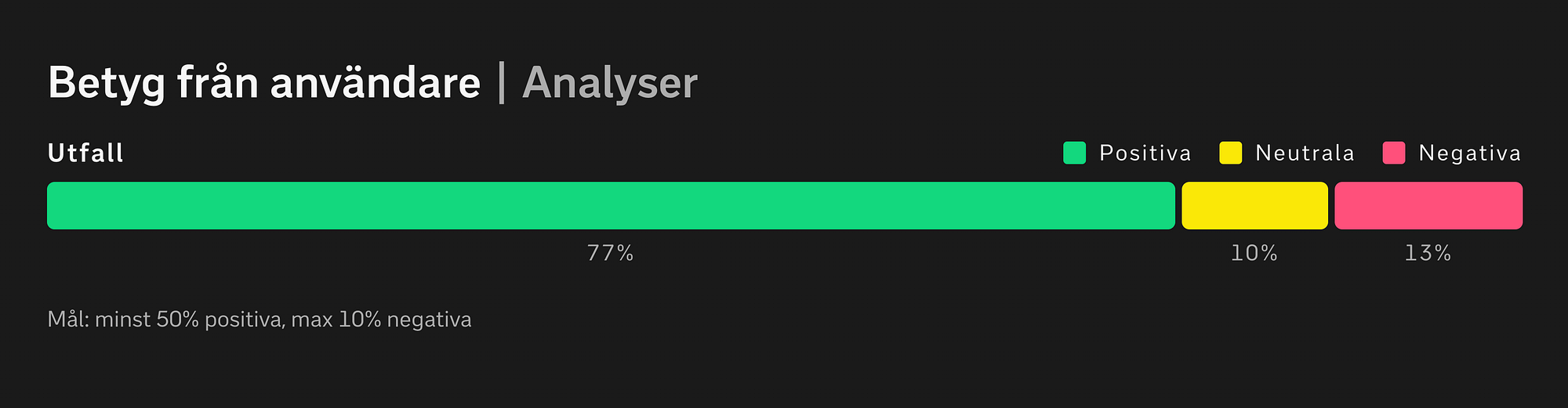
Nu är detta en relativt ny funktion i BI-systemet — samt känsligt att dela transparent vilka praktiska val som gjorts baserat på våra automatiska analyser.
Men kan dela att vi redan nu får feedback från programredaktioner som ändrat gästval, klippning (snabbare tempo!), ämnesval i talkshows samt gjort andra målgruppsanpassningar baserat på dessa analyser.
Vi är såklart inte klara
Naturligtvis kommer vi se på den här artikeln och den här lösningen som kuriosa om ett år. Modeller blir bättre och allt fler processer och delprocesser kan automatiseras, även instruktioner och utvärdering. Det kollektiva lärandet, och kunskapsspridandet som den här artikeln (vassegod!), ökar konstant.
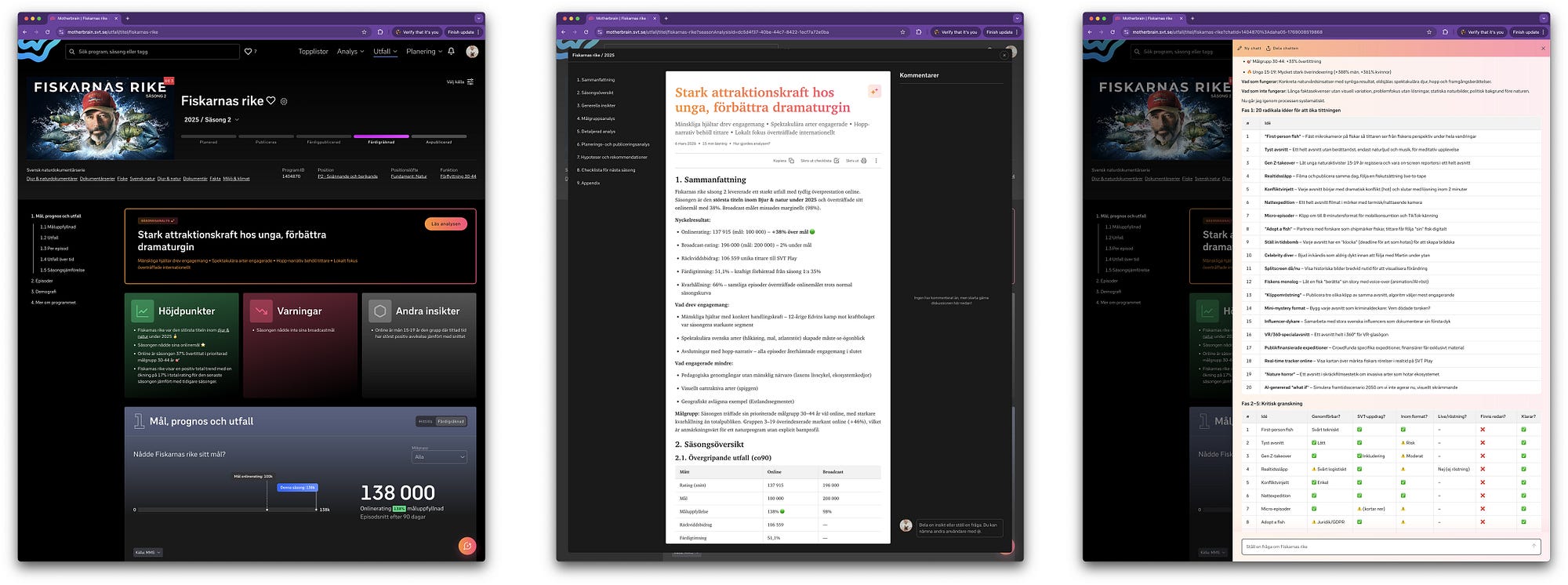
De tre olika sätten att få insikter i Motherbrain: Classic (gör det själv), AI-stödd analys (läs analys) och chattgränssnitt (fråga i naturligt språk).
En rolig utmaning för oss är att guida användarna till de tre olika sätten att använda vårt BI-verktyg:
- Motherbrain classic: Tvättad och kvalitetssäkrad data som presenteras i lättanvända rapporter. “Sanningen”. Men fortfarande gör det själv (även om vi har ett inbyggt socialt lager med kommentarer) och leta/pull jämfört med att insikterna kommer till dig/push.
- AI-stödda analyser: Rapporter med insikter och hypoteser om enskilda episoder, säsonger eller innehåll på gruppnivå. Samt även för målgrupper. Det du precis läst. Tolkning och analys av “sanningen”.
- Chattgränssnitt: Ett sätt att ställa frågor med naturligt språk där utmaningen är att instruera systemet att svara snabbt, korrekt och tydligt. Pull med möjlighet till cherry-picking och bias av “sanningen”. Men enormt kraftfullt!
Nu ser användningen ut ungefär så här: 70% / 20% / 10%. Om några år har vi vänt på siffrorna. Men det kommer kräva tålamod, pedagogik och tokens.
Samt många dollars till amerikanska techjättar.