
Jag brukar påminna mig själv om att jag är i utforskningsbranchen. Ju snabbare jag misslyckas, desto snabbare lär jag mig och blir mer framgångsrik. Ta dessa misstag som lärande och utan fruktan att göra fel.
Implementation
#1: Jag har använt korrupt data i analyser
Jag har flera gånger kommit in i nya team och inte känt till eller ignorerat spårningshistoriken. Otaliga gånger har jag dragit slutsatser på data som varit korrupt. Det har ofta handlat om spårning som gått sönder helt, eller som skickat in felaktig data.
Nu ber jag alltid om en historisk genomgång av spårningen. Saknas dokumentation och annoteringsstruktur ser jag till att den kommer igång.
Analys och slutsatser
#2: Jag har missat säsongsvariationer
Jag har ofta dragit förhastade slutsatser på data som samlats in under en för begränsad tid. Ibland har en inte tillgång till historisk data — spårning kan t.ex. saknas — och det är frestande att dra slutsatser på den lilla data en har.
Jag har genomfört A/B-test och analyser under tidsperioder som inte är signifikanta för produkten och användningen. Det kan handla om experiment för att pusha dramaserier i en Play-tjänst när dramautbudet är dåligt i slutet av maj. Eller analysera tv-tablådata under julveckan och tro att det är signifikativt beteende för hela året.
Nu frågar jag andra analytiker och kollegor vilka säsongsvariationer som är viktiga för kontexten, branschen och produkten innan jag börjar med analys eller experiment. Jag drar ut historisk data över flera år för den domän jag undersöker.

Svenskarna verkar göra sitt enda initierade vinval i samband med nyår (Källa: Google Trends)
#3: Jag har kommunicerat felaktig data
Kanske det jobbigaste misstaget då det innebär bristande förtroende och risk för felaktiga beslut. Felaktig data kan bero på många saker. Fel i segment, fel i filter, korrupt spårning, buggar i själva analysverktyget, UX-problem med analysverktyget, etc. Är det något misstag du till varje pris ska försöka undvika så är det detta.
Vid större eller viktiga analyser låter jag oftast en annan analytiker, helst från ett annat team, dubbelkolla mina segment, filter samt kommentera de slutsatser jag drar. Det hjälper dock inte alltid, eftersom det är lätt att göra fel. Är du osäker så kommunicera osäkerheten. Precis som när du kommunicerar resultat av användningstest och andra researchmetoder — visa ödmjukhet och undvik “så här är det”-attityd.
#4: Jag har suboptimerat
Jag har blivit så blind av effekterna av nya features och innehåll att jag inte sett att de leder till beteende som påverkar de övergripande målen negativt.
Det kan handla om att ny funktionalitet lockar till sig klick och beteende som sedan leder till hög exit rate. Samtidigt som produktens mål är att jobba för ökad time spent. Den nya funktionaliteten kan också skapa sämre lojalitet till produkten jämfört med annan funktionalitet.
Nu mäter jag alltid varenda litet experiment mot flera övergripande mål när jag genomför A/B-test. För ny funktionalitet följer jag oftast upp övergripande metrics som lojalitet, besökstid, återkommandegrad tidigare sidor samt exitgrad.
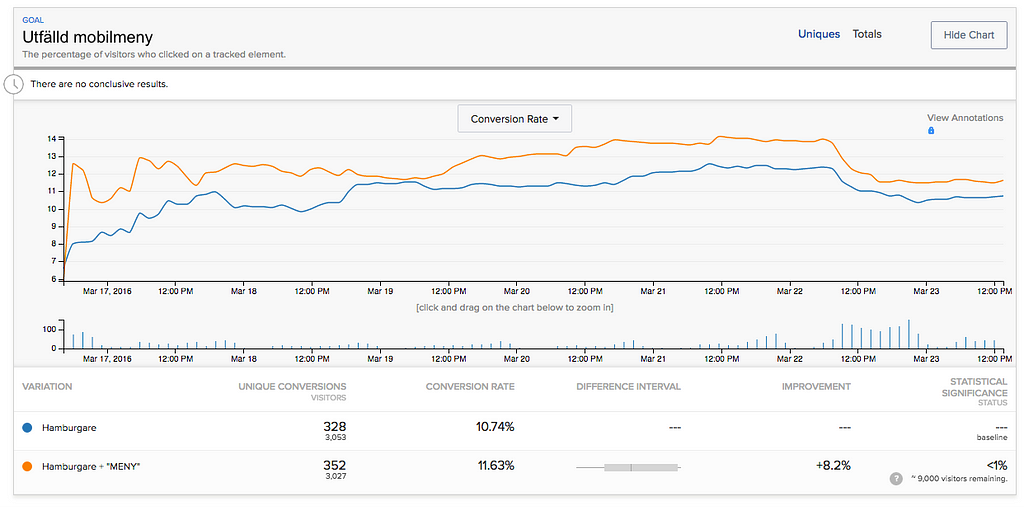
Exempel på resultat från ett pågående A/B-test som vid första anblick ser ut att gå bra

I själva verket kan vi inte se någon positiv effekt på det övergripande målet
#5: Jag har missat kannibalism
Många gånger har jag missat att beteende och klick bara flyttar runt i tjänsten när en A/B-testar eller lägger till ny funktionalitet. Det kan vid en första anblick verka som att experimentet går bra och genererar värde. Men i själva verket tas klick från för affären mer värdefullt beteende. Det kan också vara så att klick flyttas till funktionalitet som påverkar lojaliteten sämre än där de kom ifrån.
Nu märker jag upp alla element i den vy jag A/B-testar för att se hur klicken flyttas jämfört med originalversionen. Jag försöker också analysera hur kannibalismen påverkar lojalitet och övergripande mål.
#6: Jag har dragit kvantitativa slutsatser av för lite data
Ibland finns det helt enkelt för lite data. Många gånger har jag frestats att ändå dra kvantitativa slutsater och generalisera. Ibland har det gått helt fel. Det kan handla om att jag inte har kunnat få ut viss data på det aggregerade sätt jag önskar. Då har jag t.ex.:
- manuellt gått igenom de 50 mest använda sidorna i en specifik rapport, eller
- gjort många stickprov.
Det kan ge uppslag till hypoteser. Men det är också farligt att dra generella slutsatser på det här sättet. Har du ett utpräglat longtailbeteende kanske de 50 mest använda vyerna både står för insignifikant beteende och en mycket liten andel av total användning.
Nuförtiden använder jag bara otillräcklig kvantitativ data för att generera hypoteser (med kommunicerad högre risk).
#7: Jag har dragit förhastade slutsatser om orsak och verkan
Att korrelationen mellan två variabler är hög indikerar ett samband (ex antal konverteringar och antal besök från sök). Förhastat har jag många gånger dragit slutsatser om vad som är orsak och vad som är verkan. När det i själva verket kan vara tvärtom. En ytterligare svårighet kan vara att det är en tredje variabel som är den egentliga orsaken till sambandet (t.ex. antal spenderade kronor i AdWords).
Nu försöker jag göra en orsaksambandsanalys när det är vitalt att analysen blir helt rätt (kanske inte för hypotesgenerering på featurenivå). Jag försöker utesluta tredje variabler. Jag undersöker kausalitet och tittar på att förändringar i en variabel också återspeglar sig i den andra variabeln.
#8: Jag har låtit förutfattade meningar påverka analysen
Flera gånger har jag haft en hypotes som jag med hjälp av kvantitativ data och experiment försökt att validera. Istället för att ha öppna och neutrala ögon har jag omedvetet analyserat data på ett förutfattat sätt. Det leder bara till olycka. När en feature väl skeppas och resultat från A/B-test eller kvantitativa analyser inte visar sig hålla över tid är det du som står där och ska försöka förklara varför.
Nu för tiden låter jag någon annan analytiker, allra helst utanför teamet, gå igenom större analyser innan de presenteras.
A/B-testing och experiment
#9: Jag har genomfört för begränsade A/B-test
Jag har avslutat A/B-test för tidigt, även när jag fått statistisk signifikans, och dragit slutsatser av resultatet. Resultatet har sedan kommunicerats och skapat förväntningar hos intressenter och beställare om framtida varaktiga effekter.
Flera gånger har det visat sig att det funnits en initial nyfikenhet och användning av ny funktionalitet hos användare, men efter några dagar/vecka minskar intresset och lojalitet till den nya funktionaliteten sjunker. Detta har varit speciellt vanligt om en har en stor andel lojala användare som använder produkten ofta.
I andra fall har användarens förändringskurva varit så lång att experimenten bara täckt in den första negativa effektförändringen. Den långsiktiga positiva effekten har tagit så lång tid att etableras att förändringen inte hinner inkluderas i A/B-testet.
Nu genomför jag så långa experiment jag kan för att minska risken att dra förhastade slutsatser. Jag följer upp hur trenden för återkommandegrad till funktionaliteten ser ut (använd cohortdiagram). Jag gör uppföljningstest. Jag är noga med att sätta förväntningar om att uppföljning över tid kommer visa om funktionaliteten skapar värde eller behöver tas bort. Skeppning av feature är inte samma sak som skapat värde eller att funktionaliteten ska vara kvar i produkten.
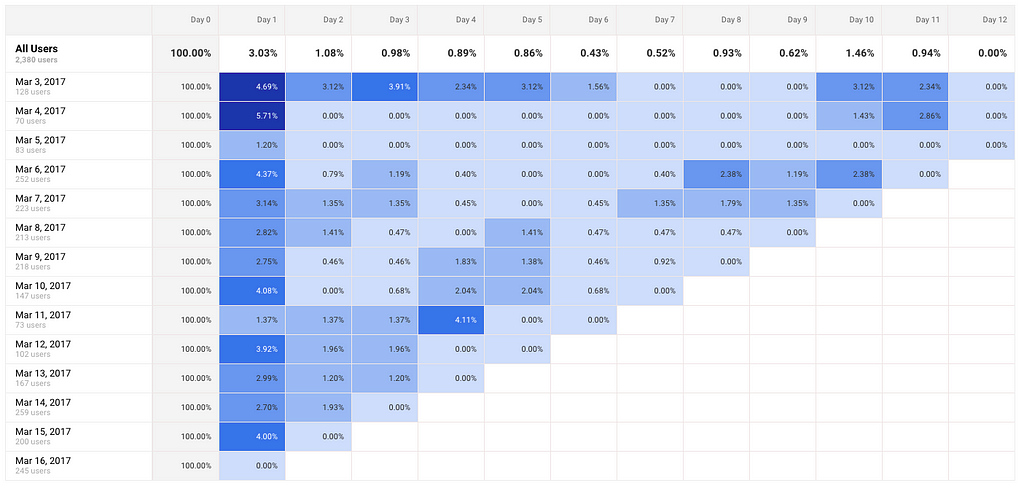
Exempel på cohortdiagram som visar hur stor andel av användare som återkommer till en funktionalitet
#10: Jag har dragit slutsatser av för få experiment
Jag har ibland struntat i att genomföra uppföljande A/B-test. Det kan t.ex. handla om att test tar för lång tid att genomföra. Risken att slump, innehåll, tidpunkt, säsong etc har påverkat resultatet av experimentet blir då betydligt högre jämfört med att konsekvent genomföra uppföljningstest.
Nu genomför jag i princip alltid uppföljande A/B-test. Visar originaltest och uppföljningstest på samma resultat är säkerheten i din analys betydligt högre än vid ett enstaka test.
#11: Jag har kommunicerat resultat av A/B-test som förväntade framtida effekter
Jag har flera gånger presenterat resultat (“Element A gav 70% högre CTR än original-elementet”) på ett sådant sätt att intressenter, team och beställare förväntat sig liknande resultat vid release.
Det är viktigt att förstå att den statistiska signifikansen endast gäller att element A har en högre CTR än originalet. Förutom att vi inte har tillräckligt hög säkerhet på nivån av effektförbättringen kan innehåll, säsong och andra faktorer påverka förbättringsnivån.
Numera kommunicerar jag bara om en variation presterar bättre eller sämre än originalet.
#12: Jag har struntat i att skicka A/B-testdata till mitt analysverktyg
Det har hänt att jag glömt, eller struntat i, att integrera mitt A/B-testverktyg med Google eller Adobe Analytics. Det leder till två problem:
- Jag saknar data för viktiga metrics och segment eftersom A/B-testverktyget oftast inte spårar allt som mitt analysverktyg kan göra.
- Jag har bara en källa till data vilket blir en risk om implementationen av testet varit felaktig.
Jag är noga med att integrera t.ex. Optimizely med Google eller Adobe Analytics. Jag följer upp att resultatet ser likadant ut i både A/B-testverktyg och analysverktyg.
#13: Jag har missat att segmentera A/B-test
Flera gånger har jag för tidigt avfärdat hypoteser när jag gått igenom resultat av genomförda A/B-test. Det har på ytan visat sig att det generiska resultatet inte visat på någon förbättring av effekter alls.
I själva verket har det visat sig att det funnits stora förbättringar inom vissa segment (förstagångsbesökare, besökare från kampanjer, mobilanvändare, etc) som inte syns på den aggregerade nivån.
Förutom att vi kan personalisera upplevelse, design och landningar är det också mycket svårt att få till stora positiva förändringar på generiska besökare i A/B-test. Generiskt testande ger generiska resultat, som någon skrev.
Jag tycker att det bästa är att segmentera redan innan en genomför test. Alltså sätta upp olika test per segment istället för att segmentera resultatet. Användare i segment har inte sällan olika behov. Försök förstå dem, adressera dem och utnyttja optimeringsmöjligheten. Testa inte samma generiska upplevelse. Uppsidan blir ofta större vid kontextoptimering.
Förutsättningar
#14: Jag har underskattat användarens motivation
Det är inte ovanligt att intressenter och beställare går på konferenser och läser bloggar som visar på fantastiska resultat av A/B-test. På små förändringar. Förväntningar på stora, varaktiga resultat av A/B-test är höga. Flera gånger har jag accepterat uppdrag där utsikterna för att förbättra effekterna har varit små.
I många fall har det har visat sig att användarna har varit så motiverade att lösa sina problem att en kommer undan med ganska usel UX. T.ex. boka läkartid online, göra en adressändring, ansöka om bygglov, köpa en produkt som bara finns på ett ställe. Det behöver inte vara waste att jobba med dessa processer, men risken finns att förbättringarna blir så små att optimeringsarbetet inte blir kostnadseffektivt.
Nu försöker jag först förstå hur stor motivationen är hos användaren. Om användaren kan genomföra processen på andra sätt eller hos konkurrenter. Och hur höga barriärerna är för alternativa sätt.
#15: Jag har lagt ned analysstid på saker som jag inte kan påverka
Det är inte ovanligt att jag tagit uppdrag där kunden “vill börja jobba datadrivet”. Kunden har många gånger varit bestämd kring vad som ska göras, och det har varit svårt att påverka detta. Det kan handla om att genomföra A/B-test eller sätta upp prydnadsdashboards och rapporter.
I själva verket har mycket av arbetet varit ren och skär waste. Kultur och politik hos organisationen har ändå gjort att beslut inte tas på data. Bara på “rätt” data. Dashboards och rapporter används inte för analys och hypotesgenerering utan bara för rapportering. A/B-test sätts upp på för lite trafik. En propsar på att genomföra experiment som ger uppenbart begränsat värde och insikter.
Fler av dessa frustrerande problem kan lösas med hjälp av kunskap och coachning. Men när kultur och politik sätter stopp finns det bara en sak att göra om du vill växa eller åstadkomma något: byta uppdrag eller arbetsgivare.
Nuförtiden är jag noggrann med att åtminstone försöka förstå hur kultur och politik fungerar i organisationen innan jag tackar ja till ett uppdrag. En bra fråga att ställa för att snabbkolla kulturen är “När tog ni senast bort en skeppad feature från er produkt?”. Svaret visar ofta på hur väl organisationen följer upp business outcome och agerar på data.
#16 Jag har jobbat som specialist utanför utvecklingsteamet
Ganska ofta har jag jobbat som analysresurs utanför utvecklingsteamet, speciellt när jag jobbat med flera team samtidigt. Det brukar inte sluta bra av flera skäl.
- Det är svårt att påverka prioriteringar i backloggen (som kan hindra mig).
- Det blir ofta en extra uppförsbacke trovärdighetsmässigt när en presenterar analys eller föreslår hypoteser att validera (not invented here-syndromet).
- Jag har missat produktjusteringar, buggar och insikter som bara kommuniceras inom teamet.
- Avståndet mellan konceptutvecklare/UX:are och mig har blivit för stort.
Nu försöker jag alltid se till att jag är en del av ett utvecklingsteam. Analyticsrollen ger bäst utväxling när metoderna naturligt integreras i det vanliga produktutvecklingsarbetet. I research, i hypotesvalidering, i uppföljning och i prioritering.
Ständigt lärande
Misstag gör jag hela tiden. Det är inget jag oroar mig för så länge jag lär mig och inte gör om dem (för ofta). Snarare skulle jag oroa mig om jag inte vågar testa nya metoder, verktyg eller infallsvinklar till problemlösning, förståelse och hypotesgenerering.
Kör hårt. Det är kul på vägen.
Detta inlägg publicerades ursprungligen på valtech.se 21 mars 2017.