Säg att du har 100 spännande hypoteser som bara väntar på att testas, valideras och firas. Du och ditt team hinner i snitt att testa 20 av dem under ett bättre kvartal. Och du har en hit rate på 30%. Det blir sex vinnare. Sex bra, värdeskapande idéer av 100, på ett kvartal.
Känns det som att konkurrenterna hinner med 30 bra idéer under samma tid?
Jag ska visa hur du kommer ikapp och förbi.
Bredda tratten
Det första vi behöver göra är att bredda tratten. Vi behöver komma upp i en nivå som tillräckligt sänker barriärerna för er hypotesvalidering. Alltså möjligheten att snabbt och billigt genomföra experiment.
Det kan vara:
- Köpa in A/B-testverktyg
- Bygga custom A/B-testverktyg för viktiga delar av din tjänst
- Göra det enkelt att spåra användning
- Rekrytera growth-analytiker, data engineers, analytics engineers och/eller data scientists
- Se till att all metadata finns och göra det enkelt att berika data
- Göra det enkelt att följa upp resultat
- Göra det enkelt att implementera vinnartest
- Hålla koncept disciplinerat enkla
Genom att ständigt förbättra förutsättningarna för att kunna hypotesvalidera är det inte omöjligt att ni kan komma upp till 50 experiment på 100 idéer under ett kvartal. Big win för tratten.
Taktiskt knep om det inte funkar att få ner barriärerna: Se till att teamet endast mäts på antalet genomförda experiment ett tag. Då kommer det hända grejor.
Rätt bets
Men hur väljer du rätt bets och fördubblar din hit rate? Ett kliv från 30% till 60% hit rate skulle ge oss 30 vinnare. 30 istället för sex är en femdubbling.
Vem tar beslut om vilka idéer teamet ska satsa på? Är det produktägaren? Någon informell ledare i teamet? Den som argumenterar med mest känsla och emfas? Är det chef eller ledning som baxar in prioriteringar? Eller kanske det vanligaste: kommittébeslut i teamet?
Rangordna hypoteser efter poäng
Om ni inte gjort det redan, gå över från er traditionella backlog till en hypoteslista som rangordnas efter poäng. Det finns en mängd spännande modeller för hypotesscoring (läs min artikel här), men ofta är några av dessa kriterier med:
- Värde — Hur stort affärsvärde skulle hypotesen ge om vi kan validera den?
- Lärande — Hur mycket lär vi oss om vi genomför experimentet? Lärandesprång eller bara pyttepyttelite mer än vad vi redan vet?
- Risk — Hur stor är risken för waste om vi börjar bygga experimentet men blir blockade under tiden? Eller inte kan validera hypotesen.
- Strategi — Hur väl följer hypotesen den övergripande produktstrategin?
- Målgrupp —Hur bra stödjer hypotesen prioriterade målgruppers behov?

Som jag skrev i den här artikeln är det en fördel att scora de olika hypoteserna individuellt eller i par och sedan räkna ihop den totala poängen. Tvärfunktionella team har en tendens att se hela bilden bättre än en enskild produktägare eller produktchef.
Så ett underlag för en exempelhypotes skulle kunna se ut så här, när alla mer eller mindre killgissat:

Utmaningar med demokratisk poängsättning
Det finns flera problem med den här typen av summering av röster. Precis som det gör under ständiga fyrfältsröstningar under forcerade workshops.
- Teamets sammansättning kan vara skev när det gäller specialistområde och kunskap. Vissa teammedlemmar kan sakna förmågan att uppskatta framtida effekter p.g.a. bristande erfarenhet eller bredd.
- En grupp teammedlemmar har samma bias. Det kan var vilket bias som helst. Att en specifik roll längtat efter att testa just den här hypotesen. Eller att rollen i sig har en inneboende bias att alltid prioritera upp något (t.ex. en viss teknik, en affärsutmaning eller ett uttalat – men ej validerat – användarbehov).
- Teammedlemmar över- eller underscorar konsekvent samma kriterier. Trots feedback på tidigare poängsättning. Ni vet, den ständiga riskminimeraren. Den obotlige tidsoptimisten. Den alltid förväntansfulle som ideligen överskattar uppsidan. Ni vet vilka ni är. Eller, det vet ni inte alls. Förrän svart finns på vitt.
- Teammedlemmar kan direkt eller indirekt vara påverkade av internpolitik. I riktigt tvärfunktionella team med medlemmar från olika delar av organisationen kan det här vara ett påtagligt problem. Den objektiva analysen av en hypotes spelar ingen roll. Internpolitiskt finns det viktigare skäl till varför en hypotes ska ha högst poäng.
Så hur kan du minska bias i en demokratisk poängsättning?
- Börja med att spara varje teammedlems poängsättning. Vid varje hypotesscoringomgång/produktplanering.
- När en hypotes har validerats, dokumentera ett “korrekt” resultat av varje scoringkriterie. För att undvika diskussioner kan en på förhand bestämma vilket värde hypotesen ska skapa för att exempelvis nå t.ex. en femma (ex: minst 30% förbättring av bounce rate). Lärande är mer subjektivt medan risk är relativt enkel att följa upp. Förslagsvis väljer teamet ut ett par personer som bäst kan uppskatta värdet av lärandet, som facitsättare.
- Varje teammedlem får ett resultat över hur väl den lyckades förutse resultatet
- Ju bättre resultat, desto mer värd blir teammedlemmens röst i kommande poängsättningsomgång
Easy!
Exempel: Poängsättningsförmåga glidande fem senaste experiment
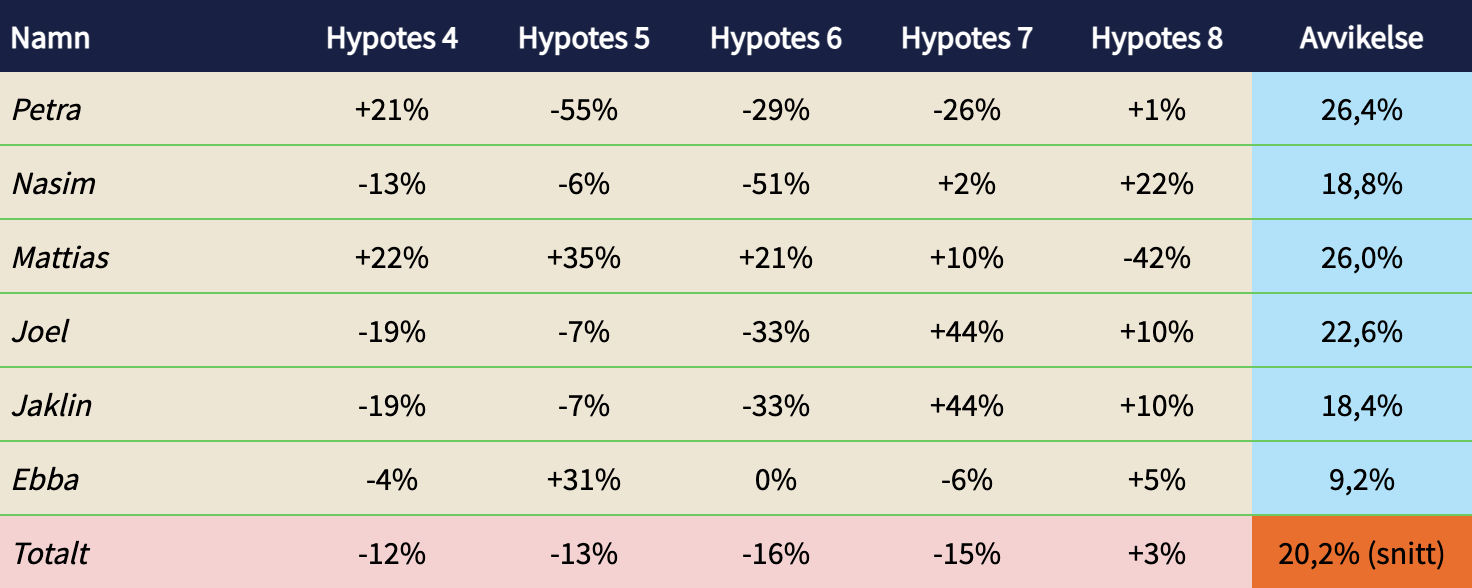
Kolla in exemplet här ovan. Petra och Mattias har lyckats särskilt bra med sin oförmåga att se in i framtiden. De är faktiskt rätt mediokra på att avgöra om en idé håller eller ej. Ebba är däremot en riktig stjärna med högst begränsad avvikelse.
Är det rimligt att Petra och Mattias ska ha lika stort inflytande som Ebba vid nästa scoringtillfälle? Nej, det vore såklart högst kontraproduktivt.
(Tänk på att göra den här uppföljningen glidande, så att alla har en chans att förbättra eller försämra sig. En viss teammedlem kan vara specialist inom ett aktuellt fokusområde, och vissa förbättrar sig när de får feedback på sin kackiga poängsättning)
Fördelarna med den här transparensen:
- Vi får systematisk feedback på vilka hypoteser som är svåra att förutspå effekt av
- Vi får, på teamnivå, feedback på vilka typer av hypoteser vi under- respektive överskattar när det gäller värde, lärande och risk
- Varje teammedlem får personlig feedback på vilka kriterier och vilka hypoteser den är bra respektive dålig på att poängsätta
Nästa scoringtillfälle
Vid nästa poängsättning/produktplanering justerar vi röststyrkan efter utfallet i tabellen ovan. Petra och Mattias får varsin röst medan Ebba får tre.

Utan justering av röstvikt skulle resultatet av en exempelhypotes kunna se ut så här:

Men eftersom Ebba, som ju är dokumenterat duktig på att gissa rätt, har fler röster justeras poängen ned och hypotesen prioriteras ner:

Och genom att de som är bäst på att förutse framtiden får mer att säga till om, förbättrar vi även vår hit rate över tid. En annan fin fördel är att vi bygger in beslutsfeedbackloopar i vårt produktarbete.
Jag vet inte hur många feedbackövningar jag varit med om i den här gudsförgätna branschen (många fina och bra såklart), men när analyserade mitt team hur och varför det tog sina beslut? Varför valde vi den där idéen? Hur kunde vi överskatta uppsidan på den där dyra MVP:n så mycket?

Reflektioner
- Det här är inte för alla team eller teammedlemmar. Åtminstone inte om en ska köra med öppna namn. Kanske passar anonymisering av personer vissa team eller delar av team bättre?
- Radikal transparens kan vara känslomässigt jobbigt.
- Avsätt tid till analys och feedbackloopar för hur ni tog bra respektive dåliga prioriteringsbeslut. Varför sker avvikelser?
- Tänk på att definiera MVP och framgångsmått redan i hypotesbackloggen. Innan ni poängsätter. Låt sedan feedbackloopen inkludera hur ni kom fram till nivå på MVP och val av framgångsmått.
- Kom överens innan vilken effekt som krävs för att t.ex. värde ska få resultatet 5. Är det t.ex. 2% förbättrad lojalitet till en feature, eller 20%?
- Utvärdering av eventuella subjektiva kriterier bör i början ske i helgrupp med stöd av så mycket tillgänglig data som möjligt.
- Ska en bryta ner avvikelse per område eller typ av hypotes? Exempelvis kan vissa teammedlemmar vara väldigt duktiga på att förutse hypoteser som rör ens specialistintresse men sämre på andra. Det bör i så fall återspeglas i röststyrkan.
Pinga mig gärna om ni testat något liknande eller kommer igång med den här modellen. Eller ännu bättre: kom och jobba som Product Owner/Manager-konsult hos oss på Signific. Vi är små men har stora ambitioner att förändra hur en driver UX-research och produktutveckling i branschen.
Avslutningsvis: kolla in det här TED-talket med Ray Dalio (ja, en kan säga mycket om honom) som fick mig att ta fram den här modellen till vårt fina growth-team.